
L'intelligence artificielle révolutionne l'industrie de la musique en offrant des outils automatisés de composition, de mastering et de performance. Les algorithmes d'IA génèrent de nouvelles compositions, prédisent les succès et personnalisent l'expérience de l'auditeur, transformant la production, la distribution et la consommation de musique. Cette technologie émergente présente à la fois des opportunités passionnantes et des dilemmes éthiques difficiles.
Les modèles d'apprentissage automatique (ML) nécessitent des données d'entraînement pour fonctionner efficacement, car un compositeur a besoin de notes de musique pour écrire une symphonie. Dans le monde de la musique, où la mélodie, le rythme et l'émotion s'entremêlent, l'importance de données d'entraînement de qualité ne peut être surestimée. C'est l'épine dorsale du développement de modèles ML musicaux robustes et précis pour l'analyse prédictive, la classification des genres ou la transcription automatique.
Les données, la pierre angulaire des modèles ML
L'apprentissage automatique est intrinsèquement axé sur les données. Ces modèles informatiques apprennent des modèles à partir des données, ce qui leur permet de faire des prédictions ou de prendre des décisions. Pour les modèles de musique ML, les données d'entraînement se présentent souvent sous forme de morceaux de musique numérisés, de paroles, de métadonnées ou d'une combinaison de ces éléments. La qualité, la quantité et la diversité de ces données ont un impact significatif sur l'efficacité du modèle.

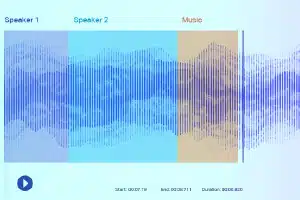
Étiquetage sonore
Avec l'étiquetage sonore, les annotateurs de données reçoivent un enregistrement et doivent séparer tous les sons nécessaires et les étiqueter. Par exemple, il peut s'agir de certains mots clés ou du son d'un instrument de musique spécifique.

Classement musical
Les annotateurs de données peuvent marquer des genres ou des instruments dans ce type d'annotation audio. La classification musicale est très utile pour organiser les bibliothèques musicales et améliorer les recommandations des utilisateurs.

Segmentation au niveau phonétique
Label et classification des segments phonétiques sur les formes d'onde et les spectrogrammes d'enregistrements d'individus chantant a capella.
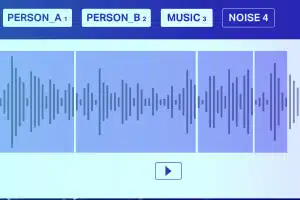
Classification sonore
À l'exception des silences/bruits blancs, un fichier audio se compose généralement des types de sons suivants Discours, Babillage, Musique et Bruit. Annotez avec précision les notes de musique pour une plus grande précision.
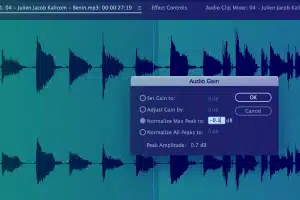
Capture d'informations sur les métadonnées
Capturez des informations importantes telles que l'heure de début, l'heure de fin, l'ID de segment, le niveau de volume, le type de son principal, le code de langue, l'ID du locuteur et d'autres conventions de transcription, etc.


