Introduction
 L'intelligence artificielle consiste à utiliser des machines pour élever la vie et le mode de vie des gens en rendant leur vie banale des tâches intéressantes et redondantes simples. L'IA n'est jamais censée être une force dominante mais une force complémentaire qui travaille en tandem avec les humains pour résoudre l'invraisemblable et ouvrir la voie à une évolution collective.
L'intelligence artificielle consiste à utiliser des machines pour élever la vie et le mode de vie des gens en rendant leur vie banale des tâches intéressantes et redondantes simples. L'IA n'est jamais censée être une force dominante mais une force complémentaire qui travaille en tandem avec les humains pour résoudre l'invraisemblable et ouvrir la voie à une évolution collective.
À l'heure actuelle, nous marchons sur la bonne voie avec des percées importantes dans tous les secteurs avec l'aide de l'IA. Si vous prenez les soins de santé, par exemple, les systèmes d'IA accompagnés de modèles d'apprentissage automatique aident les experts à mieux comprendre le cancer et à proposer des traitements pour celui-ci. Les troubles neurologiques et les problèmes comme le TSPT sont traités à l'aide de l'IA. Les vaccins sont développés à des rythmes rapides grâce à des essais cliniques et des simulations alimentés par l'IA.
Pas seulement les soins de santé, chaque industrie ou segment touché par l'IA est en train d'être révolutionné. Les véhicules autonomes, les dépanneurs intelligents, les appareils portables comme FitBit et même les caméras de nos smartphones sont capables de capturer de meilleures images de nos visages avec l'IA.
Grâce aux innovations qui se produisent dans l'espace de l'IA, les entreprises font irruption dans le spectre avec divers cas d'utilisation et solutions. Pour cette raison, le marché mondial de l'IA devrait atteindre une valeur marchande d'environ 267 milliards de dollars d'ici la fin de 2027. En outre, environ 37% des entreprises implémentent déjà des solutions d'IA dans leurs processus et produits.
Plus intéressant encore, près de 77 % des produits et services que nous utilisons aujourd'hui sont alimentés par l'IA. Alors que le concept technologique augmente considérablement dans tous les secteurs, comment les entreprises parviennent-elles à faire l'impossible avec l'IA ?

 Comment des appareils aussi simples qu'une montre prédisent-ils avec précision les crises cardiaques chez l'homme ? Comment est-il possible que les voitures et les automobiles qui ont toujours nécessité un conducteur conduisent soudainement moins sur les routes ?
Comment des appareils aussi simples qu'une montre prédisent-ils avec précision les crises cardiaques chez l'homme ? Comment est-il possible que les voitures et les automobiles qui ont toujours nécessité un conducteur conduisent soudainement moins sur les routes ?
Comment les chatbots nous font-ils croire que nous parlons à un autre humain de l'autre côté ?
Si vous observez la réponse à chaque question, cela se résume à un seul élément – les DONNÉES. Les données sont au centre de toutes les opérations et processus spécifiques à l'IA. Ce sont des données qui aident les machines à comprendre les concepts, à traiter les entrées et à fournir des résultats précis.
Toutes les principales solutions d'IA qui existent sont toutes les produits d'un processus crucial que nous appelons la collecte de données ou l'acquisition de données ou les données de formation à l'IA.
Ce guide complet a pour but de vous aider à comprendre ce que c'est et pourquoi c'est important.
Qu'est-ce que la collecte de données d'IA ?
Les machines n'ont pas leur propre esprit. L'absence de ce concept abstrait les rend dépourvus d'opinions, de faits et de capacités telles que le raisonnement, la cognition et plus encore. Ce ne sont que des boîtes ou des appareils immobiles occupant de l'espace. Pour les transformer en supports puissants, vous avez besoin d'algorithmes et surtout de données.
 Les algorithmes qui sont développés ont besoin de quelque chose à travailler et à traiter et ce quelque chose sont des données pertinentes, contextuelles et récentes. Le processus de collecte de ces données pour les machines afin qu'elles servent à leurs fins prévues s'appelle la collecte de données d'IA.
Les algorithmes qui sont développés ont besoin de quelque chose à travailler et à traiter et ce quelque chose sont des données pertinentes, contextuelles et récentes. Le processus de collecte de ces données pour les machines afin qu'elles servent à leurs fins prévues s'appelle la collecte de données d'IA.
Chaque produit ou solution compatible avec l'IA que nous utilisons aujourd'hui et les résultats qu'ils offrent découlent d'années de formation, de développement et d'optimisation. Des appareils qui offrent des itinéraires de navigation à ces systèmes complexes qui prédisent les pannes d'équipement des jours à l'avance, chaque entité a suivi des années de formation en IA pour être en mesure de fournir des résultats avec précision.
Collecte de données d'IA est l'étape préliminaire du processus de développement de l'IA qui, dès le début, détermine l'efficacité et l'efficience d'un système d'IA. C'est le processus de recherche d'ensembles de données pertinents à partir d'une myriade de sources qui aidera les modèles d'IA à mieux traiter les détails et à produire des résultats significatifs.




Comment collecter des données pour un Machine Learning ?
 C'est là que les choses commencent à devenir un peu délicates. Dès le départ, il semblerait que vous ayez en tête une solution à un problème du monde réel, vous savez que l'IA serait le moyen idéal pour y parvenir et vous avez développé vos modèles. Mais maintenant, vous êtes dans la phase cruciale où vous devez commencer vos processus de formation en IA. Vous avez besoin d'abondantes données d'entraînement d'IA avec vous pour que vos modèles apprennent des concepts et produisent des résultats. Vous avez également besoin de données de validation pour tester vos résultats et optimiser vos algorithmes.
C'est là que les choses commencent à devenir un peu délicates. Dès le départ, il semblerait que vous ayez en tête une solution à un problème du monde réel, vous savez que l'IA serait le moyen idéal pour y parvenir et vous avez développé vos modèles. Mais maintenant, vous êtes dans la phase cruciale où vous devez commencer vos processus de formation en IA. Vous avez besoin d'abondantes données d'entraînement d'IA avec vous pour que vos modèles apprennent des concepts et produisent des résultats. Vous avez également besoin de données de validation pour tester vos résultats et optimiser vos algorithmes.
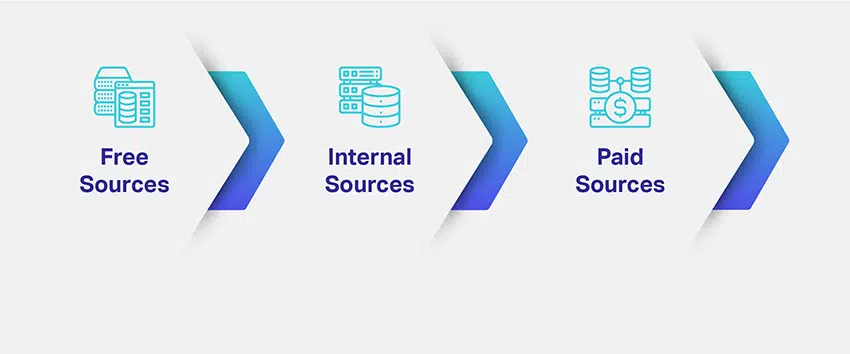
Alors, comment sourcez-vous vos données ? De quelles données avez-vous besoin et de quelle quantité ? Quelles sont les multiples sources pour récupérer les données pertinentes ?
Les entreprises évaluent le créneau et l'objectif de leurs modèles de ML et identifient des moyens potentiels de générer des ensembles de données pertinents. Définir le type de données nécessaire résout une grande partie de vos préoccupations concernant l'approvisionnement des données. Pour vous donner une meilleure idée, il existe différents canaux, avenues, sources ou supports de collecte de données :
Comment les mauvaises données affectent-elles vos ambitions en matière d'IA ?
Nous avons répertorié les trois ressources de données les plus courantes pour que vous ayez une idée de la manière d'aborder la collecte et l'approvisionnement des données. Cependant, à ce stade, il devient essentiel de comprendre également que votre décision pourrait invariablement décider du sort de votre solution d'IA.
De la même manière que des données d'entraînement d'IA de haute qualité peuvent aider votre modèle à fournir des résultats précis et opportuns, de mauvaises données d'entraînement peuvent également casser vos modèles d'IA, fausser les résultats, introduire un biais et offrir d'autres conséquences indésirables.
Mais pourquoi cela arrive-t-il ? Les données ne sont-elles pas censées entraîner et optimiser votre modèle d'IA ? Honnêtement non. Comprenons cela plus loin.
Mauvaises données – qu'est-ce que c'est ?
 Les mauvaises données sont toutes les données non pertinentes, incorrectes, incomplètes ou biaisées. Grâce à des stratégies de collecte de données mal définies, la plupart des data scientists et experts en annotations sont obligés de travailler sur de mauvaises données.
Les mauvaises données sont toutes les données non pertinentes, incorrectes, incomplètes ou biaisées. Grâce à des stratégies de collecte de données mal définies, la plupart des data scientists et experts en annotations sont obligés de travailler sur de mauvaises données.
La différence entre les données non structurées et les mauvaises données réside dans le fait que les informations sur les données non structurées sont omniprésentes. Mais en substance, ils pourraient être utiles malgré tout. En passant plus de temps, les data scientists seraient toujours en mesure d'extraire des informations pertinentes à partir d'ensembles de données non structurés. Cependant, ce n'est pas le cas avec de mauvaises données. Ces ensembles de données ne contiennent pas/peu d'informations ou d'informations utiles ou pertinentes pour votre projet d'IA ou ses objectifs de formation.
Ainsi, lorsque vous vous procurez vos ensembles de données à partir de ressources gratuites ou que vous avez des points de contact de données internes vaguement établis, il est fort probable que vous téléchargiez ou génériez de mauvaises données. Lorsque vos scientifiques travaillent sur de mauvaises données, vous perdez non seulement des heures humaines, mais vous poussez également le lancement de votre produit.
Si vous ne savez toujours pas ce que de mauvaises données peuvent avoir sur vos ambitions, voici une liste rapide :
- Vous passez d'innombrables heures à rechercher les mauvaises données et gaspillez des heures, des efforts et de l'argent sur les ressources.
- De mauvaises données pourraient vous causer des problèmes juridiques, si elles ne sont pas remarquées et peuvent réduire l'efficacité de votre IA
. - Lorsque vous prenez votre produit formé sur de mauvaises données en direct, cela affecte l'expérience utilisateur
- De mauvaises données pourraient fausser les résultats et les inférences, ce qui pourrait entraîner des réactions négatives.
Donc, si vous vous demandez s'il existe une solution à cela, il y a en fait.
Les fournisseurs de données de formation IA à la rescousse
 L'une des solutions de base consiste à opter pour un fournisseur de données (sources payantes). Les fournisseurs de données de formation à l'IA s'assurent que ce que vous recevez est précis et pertinent et que vous recevez des ensembles de données sous une forme structurée. Vous n'avez pas à vous soucier des tracas liés au déplacement d'un portail à l'autre à la recherche d'ensembles de données.
L'une des solutions de base consiste à opter pour un fournisseur de données (sources payantes). Les fournisseurs de données de formation à l'IA s'assurent que ce que vous recevez est précis et pertinent et que vous recevez des ensembles de données sous une forme structurée. Vous n'avez pas à vous soucier des tracas liés au déplacement d'un portail à l'autre à la recherche d'ensembles de données.
Tout ce que vous avez à faire est d'intégrer les données et d'entraîner vos modèles d'IA à la perfection. Cela dit, nous sommes sûrs que votre prochaine question porte sur les dépenses liées à la collaboration avec les fournisseurs de données. Nous comprenons que certains d'entre vous travaillent déjà sur un budget mental et c'est exactement vers quoi nous nous dirigeons ensuite.
Facteurs à prendre en compte lors de l'élaboration d'un budget efficace pour votre projet de collecte de données
La formation à l'IA est une approche systématique et c'est pourquoi la budgétisation en fait partie intégrante. Des facteurs tels que le retour sur investissement, l'exactitude des résultats, les méthodologies de formation, etc. doivent être pris en compte avant d'investir des sommes considérables dans le développement de l'IA. Beaucoup de chefs de projet ou de chefs d'entreprise tâtonnent à ce stade. Ils prennent des décisions hâtives qui entraînent des changements irréversibles dans leur processus de développement de produits, les obligeant finalement à dépenser plus.
Cependant, cette section vous donnera les bonnes idées. Lorsque vous vous asseyez pour travailler sur le budget de la formation en IA, trois choses ou facteurs sont inévitables.

Regardons chacun en détail.
Le volume de données dont vous avez besoin
Nous avons toujours dit que l'efficacité et la précision de votre modèle d'IA dépendaient de la quantité d'entraînement qu'il a subi. Cela signifie que plus le volume d'ensembles de données est important, plus l'apprentissage est important. Mais c'est très vague. Pour chiffrer cette notion, Dimensional Research a publié un rapport qui a révélé que les entreprises ont besoin d'au moins 100,000 XNUMX exemples d'ensembles de données pour former leurs modèles d'IA.
Par 100,000 100,000 ensembles de données, nous entendons XNUMX XNUMX ensembles de données pertinents et de qualité. Ces ensembles de données doivent avoir tous les attributs, annotations et informations essentiels nécessaires à vos algorithmes et modèles d'apprentissage automatique pour traiter les informations et exécuter les tâches prévues.
Comme il s'agit d'une règle générale, comprenons en outre que le volume de données dont vous avez besoin dépend également d'un autre facteur complexe qui est le cas d'utilisation de votre entreprise. Ce que vous avez l'intention de faire avec votre produit ou votre solution détermine également la quantité de données dont vous avez besoin. Par exemple, une entreprise qui crée un moteur de recommandation aurait des exigences de volume de données différentes de celles d'une entreprise qui crée un chatbot.
Stratégie de tarification des données
Lorsque vous avez terminé de finaliser la quantité de données dont vous avez réellement besoin, vous devez ensuite travailler sur une stratégie de tarification des données. En termes simples, cela signifie comment vous paieriez pour les ensembles de données que vous procurez ou générez.
En général, ce sont les stratégies de prix conventionnelles suivies sur le marché :
| Type de données | Stratégie de prix |
|---|---|
| Prix par fichier image unique | |
| Prix par seconde, minute, heure ou image individuelle | |
| Prix à la seconde, à la minute ou à l'heure | |
| Prix par mot ou phrase |
Mais attendez. C'est encore une règle d'or. Le coût réel d'achat des ensembles de données dépend également de facteurs tels que :
- Le segment de marché unique, la démographie ou la géographie d'où les ensembles de données doivent être extraits
- La complexité de votre cas d'utilisation
- De combien de données avez-vous besoin ?
- Votre temps de commercialisation
- Toutes les exigences sur mesure et plus
Si vous observez, vous saurez que le coût d'acquisition de grandes quantités d'images pour votre projet d'IA pourrait être moindre, mais si vous avez trop de spécifications, les prix pourraient augmenter.
Vos stratégies d'approvisionnement
C'est délicat. Comme vous l'avez vu, il existe différentes manières de générer ou de sourcer des données pour vos modèles d'IA. Le bon sens voudrait que les ressources gratuites soient les meilleures, car vous pouvez télécharger gratuitement les volumes requis d'ensembles de données sans aucune complication.
À l'heure actuelle, il semblerait également que les sources payantes soient trop chères. Mais c'est là qu'une couche de complication s'ajoute. Lorsque vous vous procurez des ensembles de données à partir de ressources gratuites, vous passez un temps et des efforts supplémentaires à nettoyer vos ensembles de données, à les compiler dans un format spécifique à votre entreprise, puis à les annoter individuellement. Vous engagez des coûts opérationnels dans le processus.
Avec les sources payantes, le paiement est unique et vous obtenez également des ensembles de données prêts à l'emploi en main au moment où vous en avez besoin. Le rapport coût-efficacité est ici très subjectif. Si vous pensez pouvoir vous permettre de passer du temps à annoter des ensembles de données gratuits, vous pouvez budgétiser en conséquence. Et si vous pensez que votre concurrence est féroce et avec un temps de mise sur le marché limité, vous pouvez créer un effet d'entraînement sur le marché, vous devriez préférer les sources payantes.
La budgétisation consiste à décomposer les détails et à définir clairement chaque fragment. Ces trois facteurs devraient vous servir de feuille de route pour votre processus de budgétisation de la formation en IA à l'avenir.
Économisez-vous sur les dépenses grâce à l'acquisition de données en interne ?
 Lors de la budgétisation, nous avons exploré comment les ressources gratuites vous obligent à dépenser plus à long terme. À ce stade, vous vous seriez automatiquement interrogé sur la rentabilité du processus d'acquisition de données en interne.
Lors de la budgétisation, nous avons exploré comment les ressources gratuites vous obligent à dépenser plus à long terme. À ce stade, vous vous seriez automatiquement interrogé sur la rentabilité du processus d'acquisition de données en interne.
Nous savons que vous hésitez encore sur les sources payantes et c'est pourquoi cette section dissipera votre scepticisme à ce sujet et fera la lumière sur les coûts cachés impliqués dans la génération de données en interne.
L'acquisition de données en interne est-elle chère ?
Oui, ça l'est!
Maintenant, voici une réponse élaborée. Les dépenses sont tout ce que vous dépensez. En discutant des ressources gratuites, nous avons révélé que vous dépensiez de l'argent, du temps et des efforts dans le processus. Cela s'applique également à l'acquisition de données en interne.
 Étant donné que vous disposez de points de contact ou d'entonnoirs de données personnalisés, cela ne signifie pas que vous auriez ensembles de données prêts pour la machine à la fin. Les données que vous générez seront toujours pour la plupart brutes et non structurées. Vous pouvez avoir toutes les données dont vous avez besoin en un seul endroit, mais ce que les données contiennent sera partout.
Étant donné que vous disposez de points de contact ou d'entonnoirs de données personnalisés, cela ne signifie pas que vous auriez ensembles de données prêts pour la machine à la fin. Les données que vous générez seront toujours pour la plupart brutes et non structurées. Vous pouvez avoir toutes les données dont vous avez besoin en un seul endroit, mais ce que les données contiennent sera partout.
En fin de compte, vous finirez par dépenser pour payer vos employés, data scientists, annotateurs, professionnels de l'assurance qualité, etc. Vous dépenserez également pour des abonnements aux outils d'annotation et
maintenance des CMS, CRM et autres dépenses d'infrastructure.
En outre, les ensembles de données sont liés à des problèmes de biais et de précision, dont vous avez besoin pour les trier manuellement. Et si vous avez un problème d'attrition dans votre équipe de données de formation à l'IA, vous devrez dépenser pour recruter de nouveaux membres, les orienter vers vos processus, les former à utiliser vos outils et plus encore.
Vous finirez par dépenser plus que ce que vous gagneriez à long terme. Il y a aussi des frais d'annotation. À un moment donné, le coût total encouru pour travailler avec des données internes est :
Coût encouru = nombre d'annotateurs * coût par annotateur + coût de la plate-forme
Si votre calendrier de formation à l'IA est prévu sur des mois, imaginez les dépenses que vous encourriez systématiquement. Alors, est-ce la solution idéale aux problèmes d'acquisition de données ou existe-t-il une alternative ?
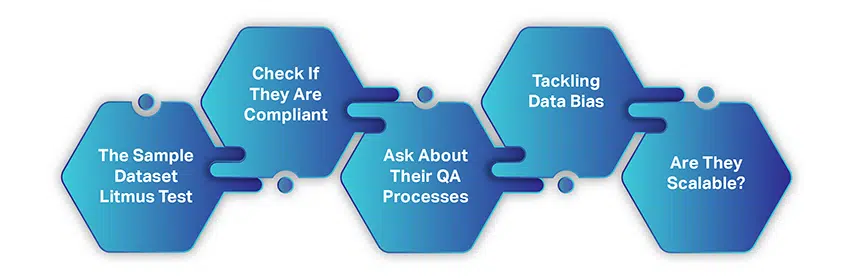
Comment choisir la bonne société de collecte de données AI
Choisir une entreprise de collecte de données d'IA n'est pas aussi compliqué ou chronophage que de collecter des données à partir de ressources gratuites. Il n'y a que quelques facteurs simples que vous devez prendre en compte, puis serrer la main pour une collaboration.
Lorsque vous commencez à rechercher un fournisseur de données, nous supposons que vous avez suivi et pris en compte tout ce dont nous avons discuté jusqu'à présent. Cependant, voici un petit récapitulatif :
- Vous avez un cas d'utilisation bien défini en tête
- Votre segment de marché et vos exigences en matière de données sont clairement établis
- Votre budget est au point
- Et vous avez une idée du volume de données dont vous avez besoin
Une fois ces éléments cochés, voyons comment rechercher le fournisseur de services de données d'entraînement idéal.