
L'image dit mille mots est un dicton assez courant que nous avons tous entendu. Maintenant, si une image pouvait dire mille mots, imaginez ce qu'une vidéo pourrait dire ? Un million de choses, peut-être. L'apprentissage par ordinateur est l'un des sous-domaines révolutionnaires de l'intelligence artificielle. Aucune des applications révolutionnaires qui nous ont été promises, telles que les voitures sans conducteur ou les caisses intelligentes, n'est possible sans annotation vidéo.
L'intelligence artificielle est utilisée dans plusieurs secteurs pour automatiser des projets complexes, développer des produits innovants et avancés et fournir des informations précieuses qui changent la nature de l'entreprise. La vision par ordinateur est l'un de ces sous-domaines de l'IA qui peut complètement modifier le fonctionnement de plusieurs industries qui dépendent de quantités massives d'images et de vidéos capturées.
La vision par ordinateur, également appelée CV, permet aux ordinateurs et aux systèmes associés de tirer des données significatives à partir de visuels - images et vidéos, et de prendre les mesures nécessaires en fonction de ces informations. Les modèles d'apprentissage automatique sont formés pour reconnaître des modèles et capturer ces informations dans leur stockage artificiel afin d'interpréter efficacement les données visuelles en temps réel.


Qu'est-ce que l'annotation vidéo ?
L'annotation vidéo est la technique de reconnaissance, de marquage et d'étiquetage de chaque objet dans une vidéo. Il aide les machines et les ordinateurs à reconnaître les objets en mouvement image par image dans une vidéo.
 En termes simples, un annotateur humain examine une vidéo, étiquette l'image image par image et la compile dans des ensembles de données de catégories prédéterminées, qui sont utilisées pour former des algorithmes d'apprentissage automatique. Les données visuelles sont enrichies en ajoutant des balises d'informations critiques sur chaque image vidéo.
En termes simples, un annotateur humain examine une vidéo, étiquette l'image image par image et la compile dans des ensembles de données de catégories prédéterminées, qui sont utilisées pour former des algorithmes d'apprentissage automatique. Les données visuelles sont enrichies en ajoutant des balises d'informations critiques sur chaque image vidéo.
Les ingénieurs ont compilé les images annotées dans des ensembles de données sous des conditions prédéterminées.
catégories pour former leurs modèles de ML requis. Imaginez que vous entraînez un modèle pour améliorer sa capacité à comprendre les feux de circulation. Ce qui se passe essentiellement, c'est que l'algorithme est formé sur des données de vérité terrain contenant d'énormes quantités de vidéos montrant des signaux de trafic, ce qui aide le modèle ML à prédire avec précision les règles de circulation.
Objectif de l'annotation vidéo et de l'étiquetage en ML
L'annotation vidéo est principalement utilisée pour créer un ensemble de données pour développer un modèle d'IA basé sur la perception visuelle. Les vidéos annotées sont largement utilisées pour construire des véhicules autonomes capables de détecter les panneaux de signalisation, la présence de piétons, de reconnaître les limites des voies et de prévenir les accidents dus à un comportement humain imprévisible.. Les vidéos annotées servent des objectifs spécifiques de l'industrie de la vente au détail en termes de magasins de détail gratuits et de recommandations de produits personnalisées.
Il est également utilisé dans domaines médical et de la santé, en particulier dans l'IA médicale, pour une identification précise des maladies et une assistance lors des interventions chirurgicales. Les scientifiques exploitent également cette technologie pour étudier les effets de la technologie solaire sur les oiseaux.
L'annotation vidéo a plusieurs applications dans le monde réel. Il est utilisé dans de nombreuses industries, mais l'industrie automobile exploite principalement son potentiel pour développer des systèmes de véhicules autonomes. Examinons de plus près l'objectif principal.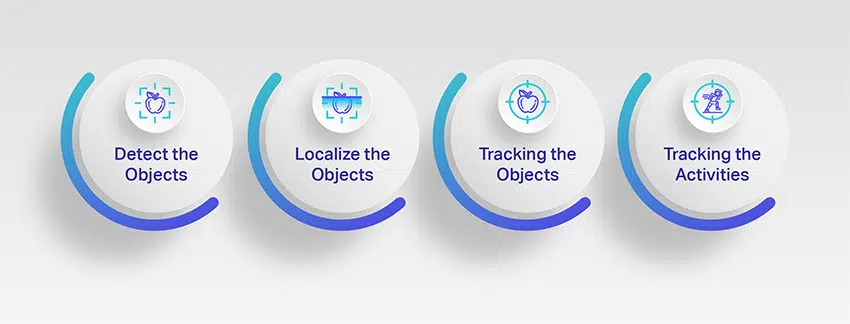
Détecter les objets
L'annotation vidéo aide les machines à reconnaître les objets capturés dans les vidéos. Puisque les machines ne peuvent ni voir ni interpréter le monde qui les entoure, elles ont besoin de l'aide de humains pour identifier les objets cibles et les reconnaître avec précision dans plusieurs cadres.
Pour qu'un système d'apprentissage automatique fonctionne parfaitement, il doit être formé sur d'énormes quantités de données pour atteindre le résultat souhaité
Localiser les objets
Il y a de nombreux objets dans une vidéo, et l'annotation de chaque objet est difficile et parfois inutile. La localisation d'objet signifie localiser et annoter l'objet le plus visible et la partie focale de l'image.
Suivi des objets
L'annotation vidéo est principalement utilisée dans la construction de véhicules autonomes, et il est crucial de disposer d'un système de suivi d'objets qui aide les machines à comprendre avec précision le comportement humain et la dynamique de la route. Il aide à suivre le flux de la circulation, les mouvements des piétons, les voies de circulation, les signaux, les panneaux de signalisation, etc.
Suivi des activités
Une autre raison pour laquelle l'annotation vidéo est essentielle est qu'elle est utilisée pour former la vision par ordinateurML basés sur des projets pour estimer avec précision les activités et les poses humaines. L'annotation vidéo aide à mieux comprendre l'environnement en suivant l'activité humaine et en analysant les comportements imprévisibles. De plus, cela aide également à prévenir les accidents en surveillant les activités d'objets non statiques tels que les piétons, les chats, les chiens, etc. et en estimant leurs mouvements pour développer des véhicules sans conducteur.
Annotation vidéo vs annotation d'image
Les annotations vidéo et image sont assez similaires à bien des égards, et les techniques utilisées pour annoter les images s'appliquent également à l'annotation vidéo. Cependant, il existe quelques différences fondamentales entre ces deux éléments, qui aideront les entreprises à choisir le bon type de annotation de données dont ils ont besoin pour leur objectif spécifique.

Techniques d'annotation vidéo
L'annotation d'images et de vidéos utilise des outils et des techniques presque similaires, bien qu'elle soit plus complexe et plus laborieuse. Contrairement à une seule image, une vidéo est difficile à annoter puisqu'elle peut contenir près de 60 images par seconde. Les vidéos prennent plus de temps à annoter et nécessitent également des outils d'annotation avancés.
Méthode d'image unique
 La méthode d'étiquetage vidéo à image unique est la technique traditionnelle qui extrait chaque image de la vidéo et annote les images une par une. La vidéo est divisée en plusieurs images, et chaque image est annotée en utilisant le traditionnel annotation d'image méthode. Par exemple, une vidéo à 40 ips est décomposée en images de 2,400 XNUMX images par minute.
La méthode d'étiquetage vidéo à image unique est la technique traditionnelle qui extrait chaque image de la vidéo et annote les images une par une. La vidéo est divisée en plusieurs images, et chaque image est annotée en utilisant le traditionnel annotation d'image méthode. Par exemple, une vidéo à 40 ips est décomposée en images de 2,400 XNUMX images par minute.
La méthode de l'image unique était utilisée avant l'utilisation des outils d'annotation ; cependant, ce n'est pas un moyen efficace d'annoter une vidéo. Cette méthode prend du temps et n'offre pas les avantages d'une vidéo.
Un autre inconvénient majeur de cette méthode est que puisque la vidéo entière est considérée comme une collection d'images séparées, elle crée des erreurs dans l'identification de l'objet. Le même objet peut être classé sous différentes étiquettes dans différents cadres, ce qui fait que l'ensemble du processus perd de sa précision et de son contexte.
Le temps consacré à l'annotation de vidéos à l'aide de la méthode de l'image unique est exceptionnellement élevé, ce qui augmente le coût du projet. Même un petit projet de moins de 20 ips prendra beaucoup de temps à annoter. Il peut y avoir beaucoup d'erreurs de classification, de délais manqués et d'erreurs d'annotation.
Méthode de trame continue
 La méthode d'image continue ou d'image en continu est la plus populaire. Cette méthode utilise des outils d'annotation qui suivent les objets tout au long de la vidéo avec leur emplacement image par image. En utilisant cette méthode, la continuité et le contexte sont bien maintenus.
La méthode d'image continue ou d'image en continu est la plus populaire. Cette méthode utilise des outils d'annotation qui suivent les objets tout au long de la vidéo avec leur emplacement image par image. En utilisant cette méthode, la continuité et le contexte sont bien maintenus.
La méthode d'image continue utilise des techniques telles que le flux optique pour capturer avec précision les pixels d'une image et de la suivante et analyser le mouvement des pixels dans l'image actuelle. Il garantit également que les objets sont classés et étiquetés de manière cohérente sur toute la vidéo. L'entité est toujours reconnue même lorsqu'elle entre et sort du cadre.
Lorsque cette méthode est utilisée pour annoter des vidéos, le projet d'apprentissage automatique peut identifier avec précision les objets présents au début de la vidéo, disparaître hors de vue pendant quelques images et réapparaître à nouveau.
Si une seule méthode d'image est utilisée pour l'annotation, l'ordinateur peut considérer l'image réapparue comme un nouvel objet entraînant une mauvaise classification. Cependant, dans une méthode d'image continue, l'ordinateur considère le mouvement des images, s'assurant que la continuité et l'intégrité de la vidéo sont bien maintenues.
La méthode d'image continue est un moyen plus rapide d'annoter et offre de plus grandes capacités aux projets ML. L'annotation est précise, élimine les préjugés humains et la catégorisation est plus précise. Cependant, ce n'est pas sans risques. Certains facteurs peuvent altérer son efficacité, tels que la qualité de l'image et la résolution vidéo.






Défis courants de l'annotation vidéo
L'annotation/l'étiquetage vidéo peut poser quelques problèmes aux annotateurs. Regardons quelques points que vous devez considérer avant de commencer annotation vidéo pour la vision par ordinateur projets.
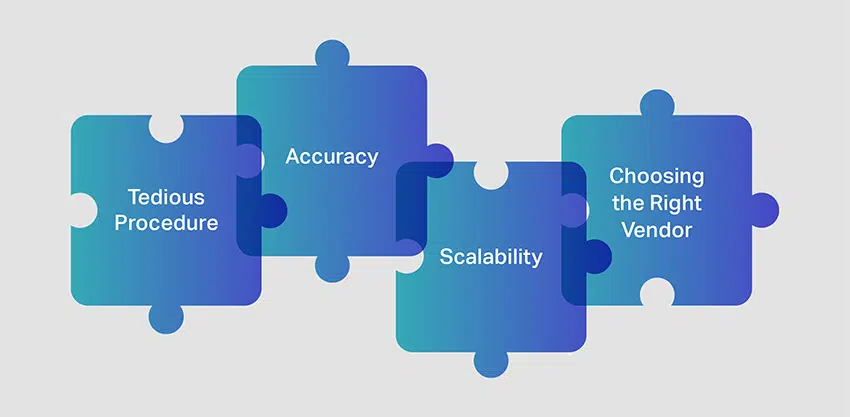
Procédure fastidieuse
L'un des plus grands défis de l'annotation vidéo est de gérer des ensembles de données vidéo qui doivent être examinés et annotés. Pour former avec précision les modèles de vision par ordinateur, il est crucial d'accéder à de grandes quantités de vidéos annotées. Étant donné que les objets ne sont pas immobiles, comme ils le seraient dans un processus d'annotation d'images, il est essentiel d'avoir des annotateurs hautement qualifiés qui peuvent capturer des objets en mouvement.
Les vidéos doivent être décomposées en clips plus petits de plusieurs images, et des objets individuels peuvent ensuite être identifiés pour une annotation précise. À moins d'utiliser des outils d'annotation, il existe un risque que l'ensemble du processus d'annotation soit fastidieux et chronophage.
Précision
Maintenir un haut niveau de précision pendant le processus d'annotation vidéo est une tâche difficile. La qualité des annotations doit être vérifiée de manière cohérente à chaque étape pour s'assurer que l'objet est suivi, classé et étiqueté correctement.
À moins que la qualité de l'annotation ne soit vérifiée à différents niveaux, il est impossible de concevoir ou d'entraîner un algorithme unique et de qualité. De plus, une catégorisation ou une annotation inexacte peut également avoir un impact sérieux sur la qualité du modèle de prédiction.
Évolutivité
En plus d'assurer l'exactitude et la précision, l'annotation vidéo doit également être évolutive. Les entreprises préfèrent les services d'annotation qui les aident à développer, déployer et mettre à l'échelle rapidement des projets ML sans impact massif sur les résultats.
Choisir le bon fournisseur d'étiquetage vidéo
 Le défi final et probablement le plus crucial de l'annotation vidéo consiste à faire appel aux services d'un fournisseur de services d'annotation de données vidéo fiable et expérimenté. Avoir un spécialiste fournisseur de services d'annotation vidéo contribuera grandement à garantir que vos projets ML sont développés de manière robuste et déployés à temps.
Le défi final et probablement le plus crucial de l'annotation vidéo consiste à faire appel aux services d'un fournisseur de services d'annotation de données vidéo fiable et expérimenté. Avoir un spécialiste fournisseur de services d'annotation vidéo contribuera grandement à garantir que vos projets ML sont développés de manière robuste et déployés à temps.
Il est également essentiel d'engager un fournisseur qui veille à ce que les normes et réglementations de sécurité soient scrupuleusement respectées. Choisir le fournisseur le plus populaire ou le moins cher n'est pas toujours la bonne décision. Vous devez rechercher le bon fournisseur en fonction des besoins de votre projet, des normes de qualité, de l'expérience et de l'expertise de l'équipe.