



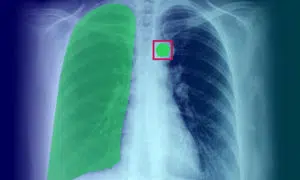
Annotation d'images médicales : définition, application, cas d'utilisation et types
L'annotation d'images médicales joue un rôle essentiel en fournissant aux algorithmes d'apprentissage automatique et aux modèles d'IA les données de formation nécessaires. Ce processus est essentiel pour

Éthique et biais : relever les défis de la collaboration homme-IA dans l'évaluation des modèles
Dans sa quête pour exploiter le pouvoir transformateur de l’intelligence artificielle (IA), la communauté technologique est confrontée à un défi crucial : garantir l’intégrité éthique et minimiser les préjugés.

The Human Touch : améliorer la créativité de l'IA grâce à une évaluation subjective
Dans le monde en évolution rapide de l’intelligence artificielle (IA), la quête de créativité n’est plus seulement une entreprise humaine. Les technologies d'IA d'aujourd'hui sont en rupture

Maximiser la pertinence de la recherche grâce à l'étiquetage des données : conseils et bonnes pratiques
Aujourd'hui, les utilisateurs sont submergés par de vastes quantités d'informations, ce qui rend complexe la recherche des informations dont ils ont besoin. La pertinence de la recherche mesure l'exactitude des informations et

Combler le fossé : intégrer l'intuition humaine dans l'évaluation des modèles d'IA
Introduction À une époque où l'intelligence artificielle (IA) façonne toutes les facettes de nos vies, l'intégration de l'intuition humaine dans l'évaluation des modèles d'IA apparaît comme

Meilleurs ensembles de données de santé open source pour les projets d'apprentissage automatique
Le système de santé mondial produit quotidiennement de grandes quantités de données médicales, qui pourraient potentiellement être utilisées pour des applications d’apprentissage automatique.

Naviguer dans la confidentialité des données dans l’IA : stratégies de conformité et d’innovation
Introduction Dans le paysage en évolution rapide de l'intelligence artificielle (IA), les entreprises comme OpenAI sont confrontées à des défis importants pour équilibrer le besoin insatiable de données avec des exigences strictes.
L'avenir des données avec la reconnaissance intelligente des caractères (ICR)
Les notes manuscrites ont un charme particulier, même dans notre monde numérique. La reconnaissance intelligente des caractères (ICR) aide à combler le fossé analogique et numérique, en convertissant le texte manuscrit

L'impact de la PNL sur les diagnostics de santé
Le traitement du langage naturel (NLP) transforme la façon dont nous interagissons avec la technologie. Il traite le langage humain pour libérer un vaste potentiel d’informations. La technologie a le même potentiel

Choisir le bon ensemble de données de reconnaissance vocale pour votre modèle d'IA
Imaginez interagir avec Siri ou Alexa. Leur capacité à comprendre notre discours est fascinante. Cette capacité découle des ensembles de données utilisés dans leur formation. Ces

Ensembles de données sur la santé : une aubaine pour l'IA dans le domaine de la santé
L’intelligence artificielle, terme autrefois principalement utilisé dans la science-fiction, est désormais une réalité qui alimente la croissance de diverses industries. Conseil en stratégie Next Move

Apprentissage par renforcement avec feedback humain : définition et étapes
L'apprentissage par renforcement (RL) est un type d'apprentissage automatique. Dans cette approche, les algorithmes apprennent à prendre des décisions par essais et erreurs, tout comme le font les humains.

Causes des hallucinations de l'IA (et techniques pour les réduire)
Les hallucinations de l'IA font référence à des cas où les modèles d'IA, en particulier les grands modèles de langage (LLM), génèrent des informations qui semblent vraies mais qui sont incorrectes ou sans rapport avec le sujet.

Qu’est-ce que la validation clinique ? Votre guide des meilleures pratiques et processus
Pensez à un scénario dans lequel un nouvel outil de diagnostic est développé. Les médecins sont enthousiasmés par son potentiel. Pourtant, avant de l'intégrer aux soins courants, ils

L’importance de l’IA éthique/de l’IA équitable et les types de préjugés à éviter
Dans le domaine en plein essor de l'intelligence artificielle (IA), l'accent mis sur les considérations éthiques et l'équité est plus qu'un impératif moral : c'est une nécessité fondamentale pour

Récapitulatif des dossiers médicaux par IA : définition, défis et meilleures pratiques
La croissance des dossiers médicaux dans le secteur de la santé est devenue à la fois un défi et une opportunité. Imaginez un monde où chaque détail d'un

Abstraction des données cliniques : définition, processus et plus encore
Les hôpitaux et cliniques reçoivent des milliers de patients chaque année. Cela nécessite un grand nombre de médecins et d’infirmières dévoués. Ils travaillent sans relâche pour prodiguer des soins

Données synthétiques dans le domaine de la santé : définition, avantages et défis
Imaginez un scénario dans lequel des chercheurs développent un nouveau médicament. Ils ont besoin de nombreuses données sur les patients pour les tests, mais il existe de sérieuses préoccupations en matière de confidentialité et de confidentialité.

Détermination d'un expert HIPAA pour la désidentification
La loi HIPAA (Health Insurance Portability and Accountability Act) établit la norme en matière de protection des données des patients dans le cadre des soins de santé. Un aspect crucial de cette démarche est la désidentification des personnes protégées.

Recherche pionnière en oncologie avec la PNL : la percée de Shaip
Télécharger l'étude de cas Dans la quête pour vaincre le cancer, les données sont aussi vitales que la détermination. Chez Shaip, nous sommes fiers d’avoir permis une avancée majeure
La puissance du traitement du langage naturel (NLP) en radiologie : améliorer le diagnostic et l'efficacité
La radiologie joue un rôle crucial dans les soins de santé. Il utilise des techniques d'imagerie telles que la tomodensitométrie, les rayons X et l'IRM pour diagnostiquer et traiter diverses affections. Langue naturelle

Le rôle du traitement du langage naturel (PNL) en oncologie
Le cancer pose un défi de santé important à l’échelle mondiale. Cela se produit lorsque les cellules se développent et se propagent de manière incontrôlée. C'est la deuxième cause de décès

Tout ce que vous devez savoir sur l'apprentissage par renforcement à partir de la rétroaction humaine
L’année 2023 a vu une augmentation massive de l’adoption d’outils d’IA comme ChatGPT. Cette montée en puissance a déclenché un débat animé et les gens discutent des avantages de l'IA,

La puissance de l'IA dans l'industrie automobile
Lorsqu’il s’agit d’intégrer l’IA dans les voitures, le monde se trouve à la croisée des chemins. Imaginez conduire sur une route très fréquentée avec l'IA, gérant votre

Avantages de la synthèse vocale dans tous les secteurs
La technologie de synthèse vocale (TTS) est une solution innovante qui convertit le texte écrit en mots parlés. Il a changé la donne dans plusieurs secteurs et a révolutionné

L'annotation de A à Z des données
Guide d'initiation à l'annotation de données : conseils et meilleures pratiques Qu'est-ce que

Guide de désidentification des données : tout ce qu'un débutant doit savoir (en 2024)
À l’ère de la transformation numérique, les établissements de santé transfèrent rapidement leurs opérations vers les plateformes numériques. Même si cela apporte de l'efficacité et des processus rationalisés, cela

L'IA générative dans les soins de santé : applications, avantages, défis et tendances futures
La santé a toujours été un domaine où l’innovation est appréciée et cruciale pour sauver des vies. Malgré les progrès technologiques, le secteur de la santé reste confronté à des défis persistants.

Différence entre l'IA responsable et l'IA éthique
Le marché mondial de l’IA, en croissance rapide, devrait atteindre 1847 2030 milliards de dollars en XNUMX. Alors que l’IA occupe une place centrale dans nos vies, savoir quel type d’IA
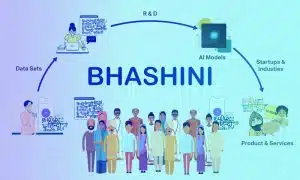
Comment Bhasini alimente l'inclusivité linguistique de l'Inde
Le Premier ministre Narendra Modi a dévoilé « Bhashini » lors de la réunion des ministres du Groupe de travail sur l’économie numérique du G20. Cette plateforme de traduction linguistique basée sur l'IA célèbre la diversité linguistique de l'Inde. Bhashini



















Annotation d'images médicales : définition, application, cas d'utilisation et types
L'annotation d'images médicales joue un rôle essentiel en fournissant aux algorithmes d'apprentissage automatique et aux modèles d'IA les données de formation nécessaires. Ce processus est essentiel pour
Éthique et biais : relever les défis de la collaboration homme-IA dans l'évaluation des modèles
Dans sa quête pour exploiter le pouvoir transformateur de l’intelligence artificielle (IA), la communauté technologique est confrontée à un défi crucial : garantir l’intégrité éthique et minimiser les préjugés.
The Human Touch : améliorer la créativité de l'IA grâce à une évaluation subjective
Dans le monde en évolution rapide de l’intelligence artificielle (IA), la quête de créativité n’est plus seulement une entreprise humaine. Les technologies d'IA d'aujourd'hui sont en rupture
Maximiser la pertinence de la recherche grâce à l'étiquetage des données : conseils et bonnes pratiques
Aujourd'hui, les utilisateurs sont submergés par de vastes quantités d'informations, ce qui rend complexe la recherche des informations dont ils ont besoin. La pertinence de la recherche mesure l'exactitude des informations et
Combler le fossé : intégrer l'intuition humaine dans l'évaluation des modèles d'IA
Introduction À une époque où l'intelligence artificielle (IA) façonne toutes les facettes de nos vies, l'intégration de l'intuition humaine dans l'évaluation des modèles d'IA apparaît comme
Meilleurs ensembles de données de santé open source pour les projets d'apprentissage automatique
Le système de santé mondial produit quotidiennement de grandes quantités de données médicales, qui pourraient potentiellement être utilisées pour des applications d’apprentissage automatique.
Naviguer dans la confidentialité des données dans l’IA : stratégies de conformité et d’innovation
Introduction Dans le paysage en évolution rapide de l'intelligence artificielle (IA), les entreprises comme OpenAI sont confrontées à des défis importants pour équilibrer le besoin insatiable de données avec des exigences strictes.
L'avenir des données avec la reconnaissance intelligente des caractères (ICR)
Les notes manuscrites ont un charme particulier, même dans notre monde numérique. La reconnaissance intelligente des caractères (ICR) aide à combler le fossé analogique et numérique, en convertissant le texte manuscrit
L'impact de la PNL sur les diagnostics de santé
Le traitement du langage naturel (NLP) transforme la façon dont nous interagissons avec la technologie. Il traite le langage humain pour libérer un vaste potentiel d’informations. La technologie a le même potentiel
Choisir le bon ensemble de données de reconnaissance vocale pour votre modèle d'IA
Imaginez interagir avec Siri ou Alexa. Leur capacité à comprendre notre discours est fascinante. Cette capacité découle des ensembles de données utilisés dans leur formation. Ces
Ensembles de données sur la santé : une aubaine pour l'IA dans le domaine de la santé
L’intelligence artificielle, terme autrefois principalement utilisé dans la science-fiction, est désormais une réalité qui alimente la croissance de diverses industries. Conseil en stratégie Next Move
Apprentissage par renforcement avec feedback humain : définition et étapes
L'apprentissage par renforcement (RL) est un type d'apprentissage automatique. Dans cette approche, les algorithmes apprennent à prendre des décisions par essais et erreurs, tout comme le font les humains.
Causes des hallucinations de l'IA (et techniques pour les réduire)
Les hallucinations de l'IA font référence à des cas où les modèles d'IA, en particulier les grands modèles de langage (LLM), génèrent des informations qui semblent vraies mais qui sont incorrectes ou sans rapport avec le sujet.
Qu’est-ce que la validation clinique ? Votre guide des meilleures pratiques et processus
Pensez à un scénario dans lequel un nouvel outil de diagnostic est développé. Les médecins sont enthousiasmés par son potentiel. Pourtant, avant de l'intégrer aux soins courants, ils
L’importance de l’IA éthique/de l’IA équitable et les types de préjugés à éviter
Dans le domaine en plein essor de l'intelligence artificielle (IA), l'accent mis sur les considérations éthiques et l'équité est plus qu'un impératif moral : c'est une nécessité fondamentale pour
Récapitulatif des dossiers médicaux par IA : définition, défis et meilleures pratiques
La croissance des dossiers médicaux dans le secteur de la santé est devenue à la fois un défi et une opportunité. Imaginez un monde où chaque détail d'un
Abstraction des données cliniques : définition, processus et plus encore
Les hôpitaux et cliniques reçoivent des milliers de patients chaque année. Cela nécessite un grand nombre de médecins et d’infirmières dévoués. Ils travaillent sans relâche pour prodiguer des soins
Données synthétiques dans le domaine de la santé : définition, avantages et défis
Imaginez un scénario dans lequel des chercheurs développent un nouveau médicament. Ils ont besoin de nombreuses données sur les patients pour les tests, mais il existe de sérieuses préoccupations en matière de confidentialité et de confidentialité.
Détermination d'un expert HIPAA pour la désidentification
La loi HIPAA (Health Insurance Portability and Accountability Act) établit la norme en matière de protection des données des patients dans le cadre des soins de santé. Un aspect crucial de cette démarche est la désidentification des personnes protégées.
Recherche pionnière en oncologie avec la PNL : la percée de Shaip
Télécharger l'étude de cas Dans la quête pour vaincre le cancer, les données sont aussi vitales que la détermination. Chez Shaip, nous sommes fiers d’avoir permis une avancée majeure
La puissance du traitement du langage naturel (NLP) en radiologie : améliorer le diagnostic et l'efficacité
La radiologie joue un rôle crucial dans les soins de santé. Il utilise des techniques d'imagerie telles que la tomodensitométrie, les rayons X et l'IRM pour diagnostiquer et traiter diverses affections. Langue naturelle
Le rôle du traitement du langage naturel (PNL) en oncologie
Le cancer pose un défi de santé important à l’échelle mondiale. Cela se produit lorsque les cellules se développent et se propagent de manière incontrôlée. C'est la deuxième cause de décès
Tout ce que vous devez savoir sur l'apprentissage par renforcement à partir de la rétroaction humaine
L’année 2023 a vu une augmentation massive de l’adoption d’outils d’IA comme ChatGPT. Cette montée en puissance a déclenché un débat animé et les gens discutent des avantages de l'IA,
La puissance de l'IA dans l'industrie automobile
Lorsqu’il s’agit d’intégrer l’IA dans les voitures, le monde se trouve à la croisée des chemins. Imaginez conduire sur une route très fréquentée avec l'IA, gérant votre
Avantages de la synthèse vocale dans tous les secteurs
La technologie de synthèse vocale (TTS) est une solution innovante qui convertit le texte écrit en mots parlés. Il a changé la donne dans plusieurs secteurs et a révolutionné
L'annotation de A à Z des données
Guide d'initiation à l'annotation de données : conseils et meilleures pratiques Qu'est-ce que
Guide de désidentification des données : tout ce qu'un débutant doit savoir (en 2024)
À l’ère de la transformation numérique, les établissements de santé transfèrent rapidement leurs opérations vers les plateformes numériques. Même si cela apporte de l'efficacité et des processus rationalisés, cela
L'IA générative dans les soins de santé : applications, avantages, défis et tendances futures
La santé a toujours été un domaine où l’innovation est appréciée et cruciale pour sauver des vies. Malgré les progrès technologiques, le secteur de la santé reste confronté à des défis persistants.
Différence entre l'IA responsable et l'IA éthique
Le marché mondial de l’IA, en croissance rapide, devrait atteindre 1847 2030 milliards de dollars en XNUMX. Alors que l’IA occupe une place centrale dans nos vies, savoir quel type d’IA
Comment Bhasini alimente l'inclusivité linguistique de l'Inde
Le Premier ministre Narendra Modi a dévoilé « Bhashini » lors de la réunion des ministres du Groupe de travail sur l’économie numérique du G20. Cette plateforme de traduction linguistique basée sur l'IA célèbre la diversité linguistique de l'Inde. Bhashini

Qu'est-ce que la PNL ? Comment ça marche, avantages, défis, exemples
Télécharger l'infographie Qu'est-ce que la PNL ? Le traitement du langage naturel (TAL) est un sous-domaine de l'intelligence artificielle (IA). Il permet aux robots d'analyser et de comprendre le langage humain,

OCR - Définition, avantages, défis et cas d'utilisation [Infographie]
L'OCR est une technologie qui permet aux machines de lire du texte et des images imprimés. Il est souvent utilisé dans les applications professionnelles, telles que la numérisation de documents pour le stockage ou le traitement, et dans les applications grand public, telles que la numérisation d'un reçu pour le remboursement des dépenses.

L'état de l'IA conversationnelle 2022
L'état de l'IA conversationnelle 2022 Qu'est-ce que l'IA conversationnelle ? Une manière programmatique et intelligente d'offrir une expérience conversationnelle en imitant des conversations avec de vraies personnes, via le numérique et les télécommunications

Qu'est-ce que la collecte de données ? Tout ce qu'un débutant doit savoir
Les modèles intelligents #AI/ #ML sont partout, qu'il s'agisse de modèles de soins de santé prédictifs, de diagnostics proactifs,

Qu'est-ce que l'étiquetage des données ? Tout ce qu'un débutant doit savoir
Télécharger l'infographie Les modèles d'IA intelligents doivent être formés de manière approfondie pour pouvoir identifier des modèles, des objets et éventuellement prendre des décisions fiables. Cependant, les formés