
Vous êtes-vous déjà demandé comment les chatbots et les assistants virtuels se réveillent lorsque vous dites « Dis Siri » ou « Alexa » ? C'est en raison de la collecte d'énoncés de texte ou de mots déclencheurs intégrés dans le logiciel qui active le système dès qu'il entend le mot de réveil programmé.
Cependant, le processus global de création de sons et de données d'énoncé n'est pas si simple. C'est un processus qui doit être réalisé avec la bonne technique pour obtenir les résultats souhaités. Par conséquent, ce blog partagera la voie à suivre pour créer de bons énoncés/mots déclencheurs qui fonctionnent de manière transparente avec votre IA conversationnelle.
Que sont les énoncés ?
Les énoncés peuvent être appelés phrases ou mots déclencheurs utilisés pour activer un modèle artificiellement intelligent. Lorsque votre modèle d'IA détecte son mot d'activation, il commence automatiquement à enregistrer la prochaine demande de l'utilisateur et répond par une action ou une réponse appropriée.
Utterance utilise le concept d'apprentissage en profondeur pour apprendre au logiciel à reconnaître les mots de réveil. Une fois que le mot de réveil active le logiciel, le système commence à capturer, décoder et traiter la demande. Lorsqu'il n'est pas utilisé, le système continue d'écouter passivement les mots déclencheurs.
Pour que votre logiciel d'IA obtienne des résultats précis, il est essentiel de capturer une pléthore d'énoncés différents pour chaque intention. Cela aide à une meilleure formation pour le modèle d'IA.
[A également lu: Aimeriez-vous savoir comment Siri et Alexa vous comprennent?]
Points à retenir lors de la création d'un référentiel d'énoncés
Maintenant que nous savons que la formation est importante pour les modèles d'IA, la prochaine chose à savoir est de savoir comment fournir des énoncés aux modèles d'IA. Habituellement, un référentiel d'énoncés est créé pour entraîner les IA conversationnelles.
Cependant, il y a plusieurs choses à retenir lors de la construction de référentiels d'énoncés. Voici les éléments à considérer :
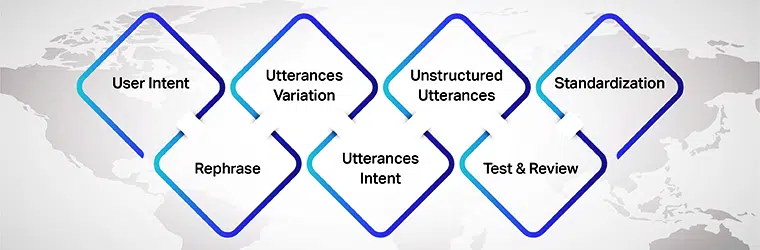
Intention de l'utilisateur
Avant tout, lors de la préparation des énoncés pour votre modèle d'IA, assurez-vous de comprendre l'intention de l'utilisateur pour laquelle vous développez les ensembles de données. Vous devez comprendre les différents énoncés que les utilisateurs peuvent saisir lors d'une conversation avec le modèle d'IA.
Variation des énoncés
Les variations sont une partie essentielle de ce processus, car plus il y a de variations pour chaque intention, meilleurs seront les résultats que vous obtiendrez. Assurez-vous donc de créer plusieurs variantes d'énoncés de l'utilisateur. Vous pouvez le faire en
- Créer des phrases courtes, moyennes et longues pour les mêmes phrases.
- Changer les mots et la longueur des phrases.
- Utiliser des mots uniques.
- Pluriel des phrases.
- Mélanger la grammaire.



