



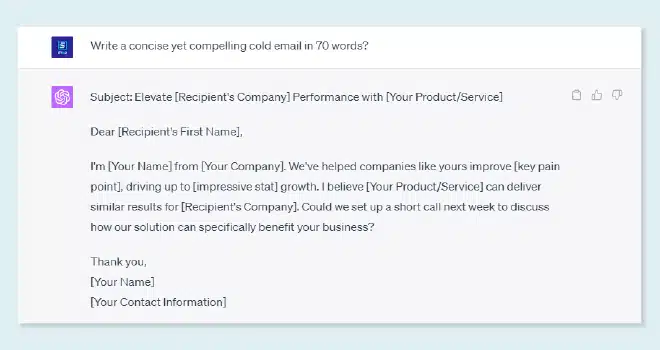











Personnes
Des équipes dédiées et formées:
- Plus de 30,000 collaborateurs pour la création de données, l'étiquetage et le contrôle qualité
- Équipe de gestion de projet accréditée
- Équipe de développement de produits expérimentée
- Équipe d'approvisionnement et d'intégration du pool de talents

Processus
Une efficacité de processus maximale est assurée avec:
- Processus robuste 6 Sigma Stage-Gate
- Une équipe dédiée de ceintures noires 6 Sigma – Responsables des processus clés & Conformité qualité
- Amélioration continue et boucle de rétroaction

Plateforme
La plateforme brevetée offre des avantages :
- Plateforme Web de bout en bout
- Une qualité irréprochable
- TAT plus rapide
- Livraison transparente
Personnes
Des équipes dédiées et formées:
- Plus de 30,000 collaborateurs pour la création de données, l'étiquetage et le contrôle qualité
- Équipe de gestion de projet accréditée
- Équipe de développement de produits expérimentée
- Équipe d'approvisionnement et d'intégration du pool de talents
Processus
Une efficacité de processus maximale est assurée avec:
- Processus robuste 6 Sigma Stage-Gate
- Une équipe dédiée de ceintures noires 6 Sigma – Responsables des processus clés & Conformité qualité
- Amélioration continue et boucle de rétroaction
Plateforme
La plateforme brevetée offre des avantages :
- Plateforme Web de bout en bout
- Une qualité irréprochable
- TAT plus rapide
- Livraison transparente



La création de PNL clinique est une tâche critique qui nécessite une énorme expertise du domaine pour être résolue. Je vois clairement que vous avez plusieurs années d'avance sur Google dans ce domaine. Je veux travailler avec vous et vous mettre à l'échelle.
Google Inc. Directeur
Mon équipe d'ingénieurs a travaillé avec l'équipe de Shaip pendant plus de 2 ans lors du développement d'API vocales pour les soins de santé. Nous avons été impressionnés par leur travail effectué dans le domaine de la PNL spécifique aux soins de santé et par ce qu'ils sont capables de réaliser avec des ensembles de données complexes.
Google Inc. Responsable de l'ingénierie