


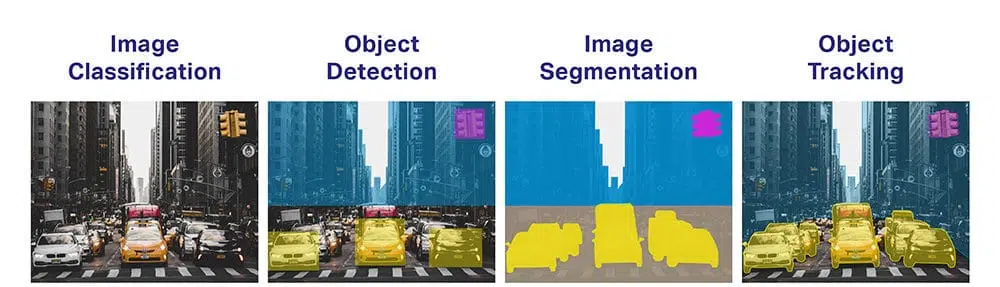
- Classification des objets: Quelle grande catégorie d'objets existe-t-il ?
- Identification de l'objet : Quel type d'objet donné existe-t-il ?
- Vérification d'objet : Quel est l'objet sur la photo ?
- Détection d'objets: Où sont les objets sur la photo ?
- Détection de point de repère d'objet : Quels sont les points clés de l'objet photographié ?
- Segmentation d'objet : Quels pixels appartiennent à l'objet dans l'image ?
- Reconnaissance d'objet : Quels objets sont sur cette photo et où sont-ils ?

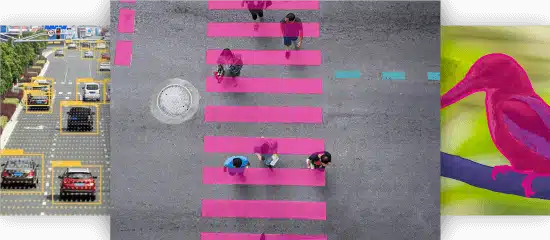


Collection d'images

Collection de vidéos

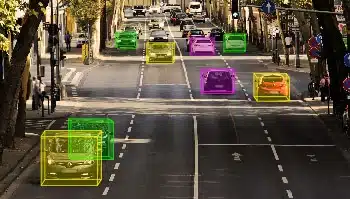
Boîtes englobantes
Cuboïdes 3D
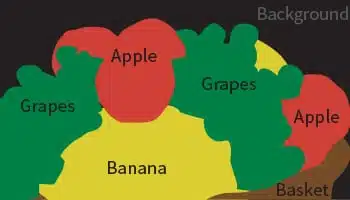
Segmentation Sémantique

Annotation de polygone

Annotation de point de repère

Segmentation de ligne

Transcription d'image
Transcription vidéo

Classification d'image
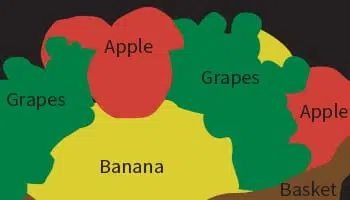
Segmentation d'image

Annotation des points clés de l'image

Classification vidéo
Segmentation vidéo

- Cas d'utilisation: Modèle ADAS embarqué
- Format: Ajouter des images
- Volume: 455,000+
- Annotation: Non

- Cas d'utilisation: Détection de point de repère
- Format: Ajouter des images
- Volume: 80,000+
- Annotation: Non

- Cas d'utilisation: Suivi des piétons
- Format: Vidéos
- Volume: 84,500+
- Annotation: Oui

- Cas d'utilisation: Reconnaissance alimentaire
- Format: Ajouter des images
- Volume: 55,000+
- Annotation: Oui

IA de santé
Entraînez les modèles ML à détecter les grains de beauté cancéreux sur les images de la peau ou à détecter les symptômes sur les IRM ou les radiographies du patient.

La reconnaissance faciale
Entraînez des modèles ML pour identifier les images de personnes en fonction des traits du visage et comparez-les avec une base de données de profils faciaux pour détecter et marquer les personnes.

Applications géospatiales
Annotation d'images satellites et de photographies UAV pour préparer des jeux de données pour le géotraitement et annoter un nuage de points 3D pour Geo.AI.

Réalité Augmentée
Avec le casque AR, placez des objets virtuels dans le monde réel. Il peut détecter des surfaces planes telles que des murs, des dessus de table et des sols - une partie très critique pour établir la profondeur et les dimensions et placer des objets virtuels dans le monde physique.

Self-Driving Cars
Plusieurs caméras capturent des vidéos sous un angle différent pour identifier les limites des feux de circulation, des routes, des voitures, des objets et des piétons à proximité pour former les voitures autonomes à diriger automatiquement le véhicule et éviter de heurter les obstacles tout en conduisant le passager en toute sécurité.

Commerce de détail / e-commerce
Avec la vision par ordinateur dans le commerce de détail, les applications peuvent offrir des recommandations personnalisées basées sur les habitudes d'achat des clients et accélérer les opérations commerciales telles que la gestion des rayons, les paiements, etc.




Personnes
Des équipes dédiées et formées:
- Plus de 30,000 collaborateurs pour la création de données, l'étiquetage et le contrôle qualité
- Équipe de gestion de projet accréditée
- Équipe de développement de produits expérimentée
- Équipe d'approvisionnement et d'intégration du pool de talents

Processus
Une efficacité de processus maximale est assurée avec:
- Processus robuste 6 Sigma Stage-Gate
- Une équipe dédiée de ceintures noires 6 Sigma – Responsables des processus clés & Conformité qualité
- Amélioration continue et boucle de rétroaction

Plateforme
La plateforme brevetée offre des avantages :
- Plateforme Web de bout en bout
- Une qualité irréprochable
- TAT plus rapide
- Livraison transparente
Personnes
Des équipes dédiées et formées:
- Plus de 30,000 collaborateurs pour la création de données, l'étiquetage et le contrôle qualité
- Équipe de gestion de projet accréditée
- Équipe de développement de produits expérimentée
- Équipe d'approvisionnement et d'intégration du pool de talents
Processus
Une efficacité de processus maximale est assurée avec:
- Processus robuste 6 Sigma Stage-Gate
- Une équipe dédiée de ceintures noires 6 Sigma – Responsables des processus clés & Conformité qualité
- Amélioration continue et boucle de rétroaction
Plateforme
La plateforme brevetée offre des avantages :
- Plateforme Web de bout en bout
- Une qualité irréprochable
- TAT plus rapide
- Livraison transparente