
Introduction
Ce guide sera extrêmement utile aux acheteurs et aux décideurs qui commencent à se tourner vers les rouages de l'approvisionnement et de la mise en œuvre des données à la fois pour les réseaux de neurones et d'autres types d'opérations d'IA et de ML.

Cet article est entièrement dédié à faire la lumière sur ce qu'est le processus, pourquoi il est inévitable, crucial
facteurs que les entreprises doivent prendre en compte lorsqu'elles abordent des outils d'annotation de données et plus encore. Donc, si vous possédez une entreprise, préparez-vous à vous éclairer car ce guide vous expliquera tout ce que vous devez savoir sur l'annotation de données.
Commençons.
Pour ceux d'entre vous qui parcourent l'article, voici quelques conseils rapides que vous trouverez dans le guide :
- Comprendre ce qu'est l'annotation de données
- Connaître les différents types de processus d'annotation de données
- Connaître les avantages de la mise en œuvre du processus d'annotation des données
- Déterminez clairement si vous devez opter pour un étiquetage des données en interne ou les externaliser
- Informations sur le choix de la bonne annotation de données également
Qu'est-ce que l'apprentissage par machine?
 Nous avons parlé de la façon dont l'annotation de données ou étiquetage des données prend en charge l'apprentissage automatique et qu'il consiste à marquer ou à identifier des composants. Mais en ce qui concerne l'apprentissage en profondeur et l'apprentissage automatique lui-même : le principe de base de l'apprentissage automatique est que les systèmes et programmes informatiques peuvent améliorer leurs résultats de manière à ressembler aux processus cognitifs humains, sans aide ni intervention humaine directe, pour nous donner des informations. En d'autres termes, ils deviennent des machines d'auto-apprentissage qui, tout comme un humain, deviennent meilleurs dans leur travail avec plus de pratique. Cette « pratique » est obtenue en analysant et en interprétant plus (et mieux) de données d'entraînement.
Nous avons parlé de la façon dont l'annotation de données ou étiquetage des données prend en charge l'apprentissage automatique et qu'il consiste à marquer ou à identifier des composants. Mais en ce qui concerne l'apprentissage en profondeur et l'apprentissage automatique lui-même : le principe de base de l'apprentissage automatique est que les systèmes et programmes informatiques peuvent améliorer leurs résultats de manière à ressembler aux processus cognitifs humains, sans aide ni intervention humaine directe, pour nous donner des informations. En d'autres termes, ils deviennent des machines d'auto-apprentissage qui, tout comme un humain, deviennent meilleurs dans leur travail avec plus de pratique. Cette « pratique » est obtenue en analysant et en interprétant plus (et mieux) de données d'entraînement.
Qu'est-ce que l'annotation de données ?
L'annotation des données est le processus d'attribution, de marquage ou d'étiquetage des données pour aider les algorithmes d'apprentissage automatique à comprendre et à classer les informations qu'ils traitent. Ce processus est essentiel pour former des modèles d'IA, leur permettant de comprendre avec précision divers types de données, tels que des images, des fichiers audio, des séquences vidéo ou du texte.
Imaginez une voiture autonome qui s'appuie sur des données issues de la vision par ordinateur, du traitement du langage naturel (NLP) et de capteurs pour prendre des décisions de conduite précises. Pour aider le modèle d'IA de la voiture à différencier les obstacles tels que les autres véhicules, les piétons, les animaux ou les barrages routiers, les données qu'il reçoit doivent être étiquetées ou annotées.
Dans l'apprentissage supervisé, l'annotation des données est particulièrement cruciale, car plus les données étiquetées sont introduites dans le modèle, plus il apprend rapidement à fonctionner de manière autonome. Les données annotées permettent de déployer des modèles d'IA dans diverses applications telles que les chatbots, la reconnaissance vocale et l'automatisation, ce qui se traduit par des performances optimales et des résultats fiables.
Qu'est-ce qu'un outil d'étiquetage/annotation de données ?
 En termes simples, il s'agit d'une plate-forme ou d'un portail qui permet aux spécialistes et aux experts d'annoter, de baliser ou d'étiqueter des ensembles de données de tous types. C'est un pont ou un support entre les données brutes et les résultats que vos modules d'apprentissage automatique produiraient en fin de compte.
En termes simples, il s'agit d'une plate-forme ou d'un portail qui permet aux spécialistes et aux experts d'annoter, de baliser ou d'étiqueter des ensembles de données de tous types. C'est un pont ou un support entre les données brutes et les résultats que vos modules d'apprentissage automatique produiraient en fin de compte.
Un outil d'étiquetage de données est une solution sur site ou basée sur le cloud qui annote des données d'entraînement de haute qualité pour les modèles d'apprentissage automatique. Alors que de nombreuses entreprises s'appuient sur un fournisseur externe pour effectuer des annotations complexes, certaines organisations disposent toujours de leurs propres outils personnalisés ou basés sur des outils gratuits ou open source disponibles sur le marché. Ces outils sont généralement conçus pour gérer des types de données spécifiques, c'est-à-dire image, vidéo, texte, audio, etc. Les outils offrent des fonctionnalités ou des options telles que des cadres de délimitation ou des polygones pour que les annotateurs de données étiquettent les images. Ils peuvent simplement sélectionner l'option et effectuer leurs tâches spécifiques.
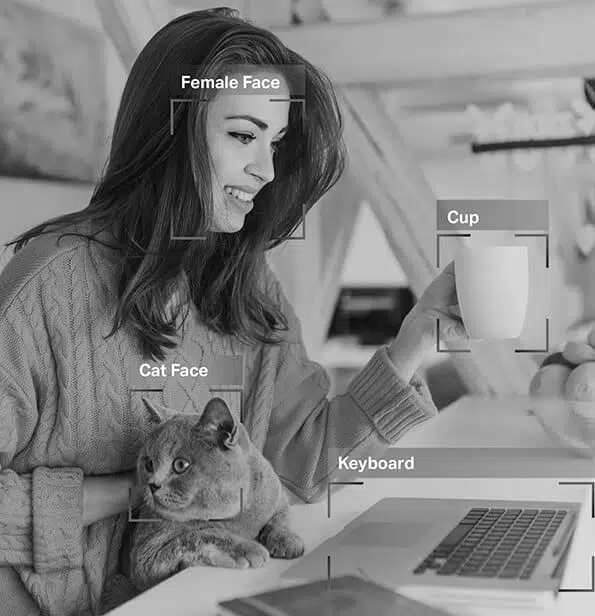
Image Annotation

À partir des ensembles de données sur lesquels ils ont été formés, ils peuvent instantanément et précisément différencier vos yeux de votre nez et vos sourcils de vos cils. C'est pourquoi les filtres que vous appliquez s'adaptent parfaitement quelle que soit la forme de votre visage, la distance qui vous sépare de votre appareil photo, etc.
Alors, comme vous le savez maintenant, annotation d'image est essentiel dans les modules qui impliquent la reconnaissance faciale, la vision par ordinateur, la vision robotique, etc. Lorsque les experts en IA forment de tels modèles, ils ajoutent des légendes, des identifiants et des mots-clés comme attributs à leurs images. Les algorithmes identifient et comprennent ensuite à partir de ces paramètres et apprennent de manière autonome.
Classification des images – La classification des images consiste à attribuer des catégories ou des étiquettes prédéfinies aux images en fonction de leur contenu. Ce type d'annotation est utilisé pour entraîner les modèles d'IA à reconnaître et à catégoriser automatiquement les images.
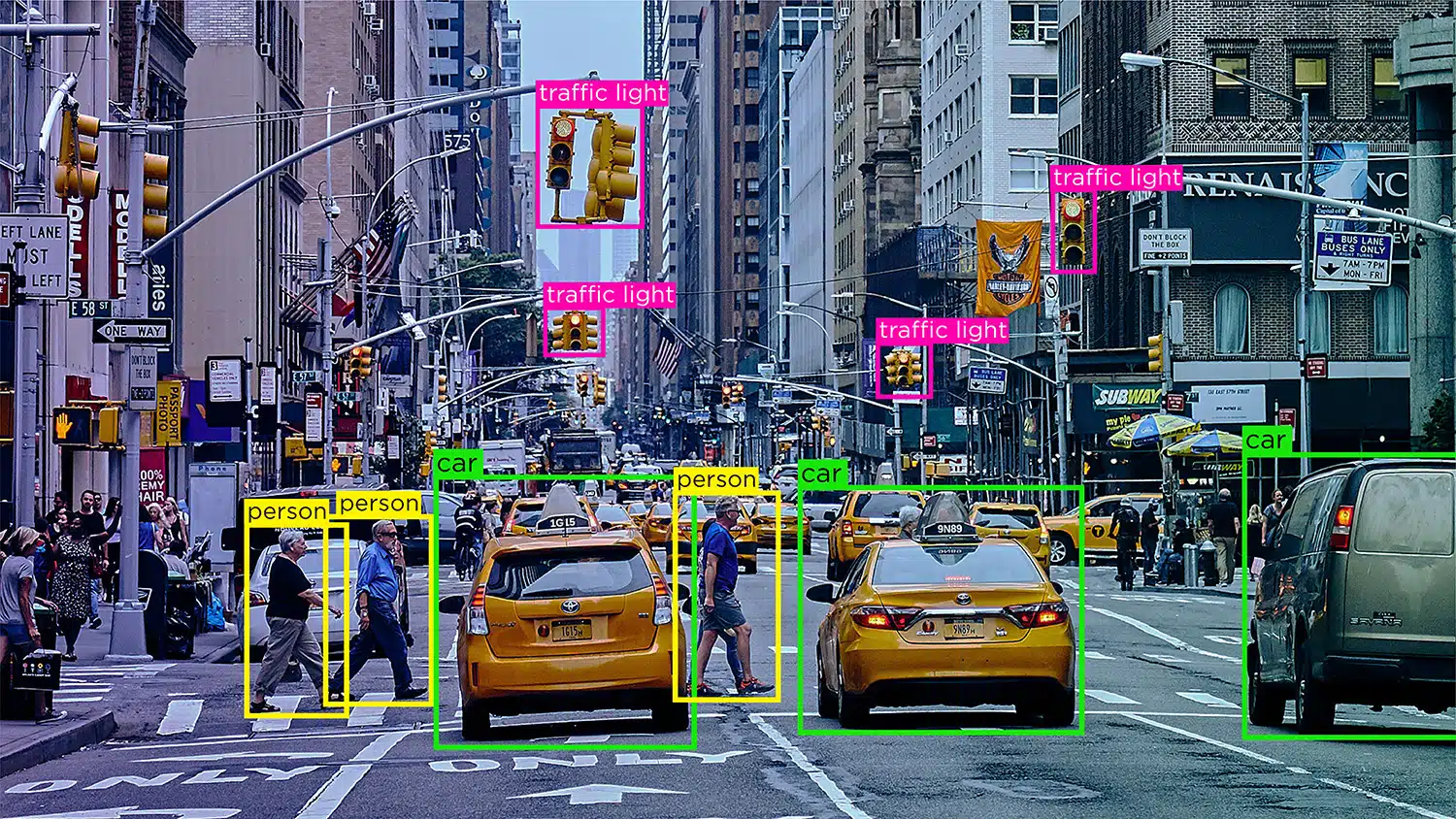
Reconnaissance/détection d'objets – La reconnaissance d'objets, ou détection d'objets, est le processus d'identification et d'étiquetage d'objets spécifiques dans une image. Ce type d'annotation est utilisé pour former des modèles d'IA afin de localiser et de reconnaître des objets dans des images ou des vidéos du monde réel.
Segmentation – La segmentation d'image consiste à diviser une image en plusieurs segments ou régions, chacun correspondant à un objet ou à une zone d'intérêt spécifique. Ce type d'annotation est utilisé pour entraîner des modèles d'IA à analyser des images au niveau du pixel, ce qui permet une reconnaissance plus précise des objets et une compréhension des scènes.
Annotation audio
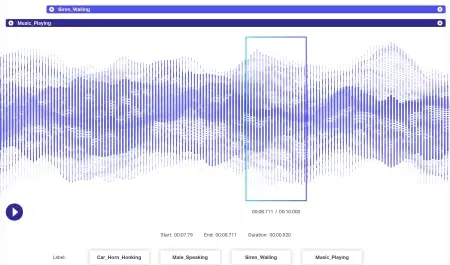
Les données audio sont encore plus dynamiques que les données d'image. Plusieurs facteurs sont associés à un fichier audio, y compris, mais sans s'y limiter, la langue, la démographie du locuteur, les dialectes, l'humeur, l'intention, l'émotion, le comportement. Pour que les algorithmes soient efficaces dans le traitement, tous ces paramètres doivent être identifiés et étiquetés par des techniques telles que l'horodatage, l'étiquetage audio, etc. En plus des indices purement verbaux, des instances non verbales comme le silence, les respirations et même le bruit de fond pourraient être annotées pour que les systèmes les comprennent de manière exhaustive.
Annotation vidéo

Alors qu'une image est immobile, une vidéo est une compilation d'images qui créent un effet d'objets en mouvement. Maintenant, chaque image de cette compilation s'appelle un cadre. En ce qui concerne l'annotation vidéo, le processus implique l'ajout de points clés, de polygones ou de cadres de délimitation pour annoter différents objets sur le terrain dans chaque image.
Lorsque ces cadres sont assemblés, le mouvement, le comportement, les modèles et plus encore peuvent être appris par les modèles d'IA en action. Ce n'est qu'à travers annotation vidéo que des concepts tels que la localisation, le flou de mouvement et le suivi d'objets pourraient être implémentés dans des systèmes.
Annotation textuelle

Aujourd'hui, la plupart des entreprises dépendent de données textuelles pour obtenir des informations et des informations uniques. Désormais, le texte peut aller des commentaires des clients sur une application à une mention sur les réseaux sociaux. Et contrairement aux images et aux vidéos qui véhiculent principalement des intentions simples, le texte est livré avec beaucoup de sémantique.
En tant qu'êtres humains, nous sommes habitués à comprendre le contexte d'une phrase, le sens de chaque mot, phrase ou phrase, à les relier à une certaine situation ou conversation, puis à réaliser le sens holistique derrière une déclaration. Les machines, en revanche, ne peuvent pas le faire à des niveaux précis. Des concepts comme le sarcasme, l'humour et d'autres éléments abstraits leur sont inconnus et c'est pourquoi l'étiquetage des données textuelles devient plus difficile. C'est pourquoi l'annotation de texte comporte des étapes plus raffinées telles que les suivantes :
Annotation sémantique – les objets, les produits et les services sont rendus plus pertinents grâce à des paramètres de marquage et d'identification des phrases clés appropriés. Les chatbots sont également conçus pour imiter les conversations humaines de cette façon.
Intention Annotation – l'intention d'un utilisateur et la langue qu'il utilise sont étiquetés pour que les machines comprennent. Avec cela, les modèles peuvent différencier une demande d'une commande, ou une recommandation d'une réservation, et ainsi de suite.
Annotation des sentiments – L'annotation de sentiment consiste à étiqueter les données textuelles avec le sentiment qu'elles véhiculent, comme positif, négatif ou neutre. Ce type d'annotation est couramment utilisé dans l'analyse des sentiments, où les modèles d'IA sont formés pour comprendre et évaluer les émotions exprimées dans le texte.

Annotation d'entité – où les phrases non structurées sont étiquetées pour les rendre plus significatives et les amener à un format compréhensible par les machines. Pour ce faire, deux aspects sont impliqués - reconnaissance d'entité nommée et liaison d'entité. La reconnaissance d'entités nommées se produit lorsque les noms de lieux, de personnes, d'événements, d'organisations et plus sont marqués et identifiés et la liaison d'entités se produit lorsque ces balises sont liées à des phrases, des expressions, des faits ou des opinions qui les suivent. Collectivement, ces deux processus établissent la relation entre les textes associés et l'énoncé qui l'entoure.
Catégorisation de texte - Les phrases ou les paragraphes peuvent être étiquetés et classés en fonction de sujets généraux, de tendances, de sujets, d'opinions, de catégories (sports, divertissements et similaires) et d'autres paramètres.
Étapes clés du processus d'étiquetage et d'annotation des données
Le processus d'annotation des données implique une série d'étapes bien définies pour garantir un étiquetage des données précis et de haute qualité pour les applications d'apprentissage automatique. Ces étapes couvrent tous les aspects du processus, de la collecte des données à l'exportation des données annotées pour une utilisation ultérieure.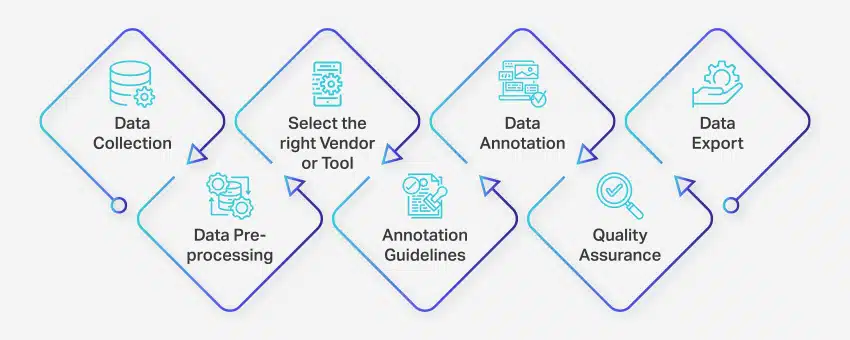
Voici comment se déroule l'annotation des données :
- Collecte des données : La première étape du processus d'annotation des données consiste à rassembler toutes les données pertinentes, telles que les images, les vidéos, les enregistrements audio ou les données textuelles, dans un emplacement centralisé.
- Prétraitement des données : Standardisez et améliorez les données collectées en redressant les images, en formatant le texte ou en transcrivant le contenu vidéo. Le prétraitement garantit que les données sont prêtes pour l'annotation.
- Sélectionnez le bon fournisseur ou outil : Choisissez un outil d'annotation de données ou un fournisseur approprié en fonction des exigences de votre projet. Les options incluent des plates-formes telles que Nanonets pour l'annotation de données, V7 pour l'annotation d'images, Appen pour l'annotation vidéo et Nanonets pour l'annotation de documents.
- Directives d'annotation : Établissez des directives claires pour les annotateurs ou les outils d'annotation afin d'assurer la cohérence et la précision tout au long du processus.
- Annotation: Étiquetez et étiquetez les données à l'aide d'annotateurs humains ou d'un logiciel d'annotation de données, en suivant les directives établies.
- Assurance qualité (AQ) : Passez en revue les données annotées pour assurer l'exactitude et la cohérence. Employez plusieurs annotations aveugles, si nécessaire, pour vérifier la qualité des résultats.
- Exportation de données : Après avoir terminé l'annotation des données, exportez les données dans le format requis. Des plates-formes telles que les nanonets permettent une exportation transparente des données vers diverses applications logicielles d'entreprise.
L'ensemble du processus d'annotation des données peut durer de quelques jours à plusieurs semaines, selon la taille, la complexité et les ressources disponibles du projet.
Fonctionnalités des outils d'annotation de données et d'étiquetage de données
Les outils d'annotation de données sont des facteurs décisifs qui pourraient faire ou défaire votre projet d'IA. Lorsqu'il s'agit de sorties et de résultats précis, la qualité des ensembles de données à elle seule n'a pas d'importance. En fait, les outils d'annotation de données que vous utilisez pour former vos modules d'IA influencent énormément vos sorties.
C'est pourquoi il est essentiel de sélectionner et d'utiliser l'outil d'étiquetage de données le plus fonctionnel et le plus approprié qui réponde aux besoins de votre entreprise ou de votre projet. Mais qu'est-ce qu'un outil d'annotation de données en premier lieu ? A quoi cela sert-il? Existe-t-il des types ? Eh bien, découvrons.
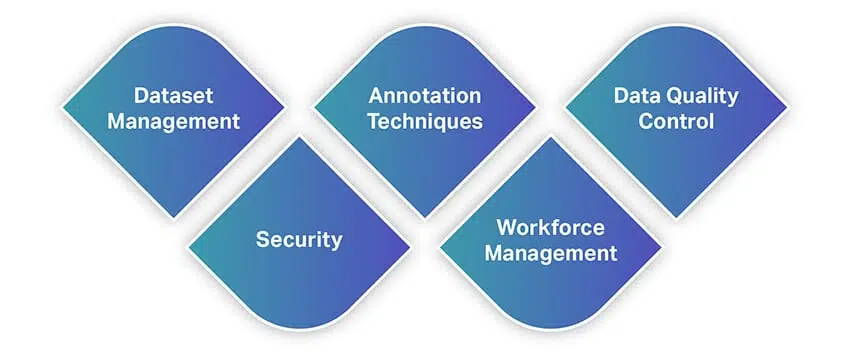
Semblables à d'autres outils, les outils d'annotation de données offrent un large éventail de fonctionnalités et de capacités. Pour vous donner une idée rapide des fonctionnalités, voici une liste de certaines des fonctionnalités les plus fondamentales que vous devriez rechercher lors de la sélection d'un outil d'annotation de données.
Gestion de jeu de données
L'outil d'annotation de données que vous avez l'intention d'utiliser doit prendre en charge les jeux de données que vous avez en main et vous permettre de les importer dans le logiciel pour l'étiquetage. Ainsi, la gestion de vos ensembles de données est la principale offre d'outils de fonctionnalité. Les solutions contemporaines offrent des fonctionnalités qui vous permettent d'importer de gros volumes de données de manière transparente, vous permettant simultanément d'organiser vos ensembles de données grâce à des actions telles que trier, filtrer, cloner, fusionner, etc.
Une fois la saisie de vos ensembles de données terminée, il faut ensuite les exporter sous forme de fichiers utilisables. L'outil que vous utilisez doit vous permettre d'enregistrer vos ensembles de données dans le format que vous spécifiez afin que vous puissiez les alimenter dans vos modèles ML.
Techniques d'annotation
C'est pour cela qu'un outil d'annotation de données est construit ou conçu. Un outil solide devrait vous offrir une gamme de techniques d'annotation pour les jeux de données de tous types. C'est à moins que vous ne développiez une solution personnalisée pour vos besoins. Votre outil doit vous permettre d'annoter des vidéos ou des images à partir de vision par ordinateur, de l'audio ou du texte à partir de PNL et de transcriptions, etc. Pour affiner cela davantage, il devrait y avoir des options pour utiliser des cadres de délimitation, une segmentation sémantique, des cuboïdes, une interpolation, une analyse des sentiments, des parties du discours, une solution de coréférence et plus encore.
Pour les non-initiés, il existe également des outils d'annotation de données alimentés par l'IA. Ceux-ci sont livrés avec des modules d'IA qui apprennent de manière autonome des modèles de travail d'un annotateur et annotent automatiquement des images ou du texte. Tel
les modules peuvent être utilisés pour fournir une assistance incroyable aux annotateurs, optimiser les annotations et même mettre en œuvre des contrôles de qualité.
Contrôle de la qualité des données
En parlant de contrôles de qualité, plusieurs outils d'annotation de données sont déployés avec des modules de contrôle de qualité intégrés. Ceux-ci permettent aux annotateurs de mieux collaborer avec les membres de leur équipe et aident à optimiser les flux de travail. Avec cette fonctionnalité, les annotateurs peuvent marquer et suivre les commentaires ou les commentaires en temps réel, suivre les identités derrière les personnes qui modifient les fichiers, restaurer les versions précédentes, opter pour le consensus d'étiquetage et plus encore.
Sécurité
Puisque vous travaillez avec des données, la sécurité doit être la priorité la plus élevée. Vous travaillez peut-être sur des données confidentielles telles que celles impliquant des données personnelles ou de la propriété intellectuelle. Ainsi, votre outil doit offrir une sécurité irréprochable en termes d'endroit où les données sont stockées et comment elles sont partagées. Il doit fournir des outils qui limitent l'accès aux membres de l'équipe, empêchent les téléchargements non autorisés et plus encore.
En dehors de cela, les normes et protocoles de sécurité doivent être respectés et respectés.
Workforce Management
Un outil d'annotation de données est également une sorte de plate-forme de gestion de projet, où des tâches peuvent être attribuées aux membres de l'équipe, un travail collaboratif peut avoir lieu, des révisions sont possibles et plus encore. C'est pourquoi votre outil doit s'intégrer à votre flux de travail et processus pour une productivité optimisée.
En outre, l'outil doit également avoir une courbe d'apprentissage minimale car le processus d'annotation des données en lui-même prend du temps. Cela ne sert à rien de passer trop de temps à simplement apprendre l'outil. Ainsi, il devrait être intuitif et transparent pour que quiconque puisse démarrer rapidement.
Quels sont les avantages de l'annotation de données ?
L'annotation des données est essentielle pour optimiser les systèmes d'apprentissage automatique et offrir une expérience utilisateur améliorée. Voici quelques avantages clés de l'annotation de données :
- Amélioration de l'efficacité de la formation : L'étiquetage des données permet de mieux former les modèles d'apprentissage automatique, d'améliorer l'efficacité globale et de produire des résultats plus précis.
- Précision accrue : Des données annotées avec précision garantissent que les algorithmes peuvent s'adapter et apprendre efficacement, ce qui se traduit par des niveaux de précision plus élevés dans les tâches futures.
- Intervention humaine réduite : Les outils avancés d'annotation de données réduisent considérablement le besoin d'intervention manuelle, rationalisent les processus et réduisent les coûts associés.
Ainsi, l'annotation des données contribue à des systèmes d'apprentissage automatique plus efficaces et précis tout en minimisant les coûts et les efforts manuels traditionnellement nécessaires pour former des modèles d'IA.
Construire ou non un outil d'annotation de données
Un problème critique et primordial qui peut survenir lors d'un projet d'annotation de données ou d'étiquetage de données est le choix de créer ou d'acheter des fonctionnalités pour ces processus. Cela peut se produire plusieurs fois dans diverses phases du projet, ou lié à différents segments du programme. En choisissant de construire un système en interne ou de s'appuyer sur des fournisseurs, il y a toujours un compromis à faire.

Comme vous pouvez probablement le constater maintenant, l'annotation de données est un processus complexe. En même temps, c'est aussi un processus subjectif. Cela signifie qu'il n'y a pas de réponse unique à la question de savoir si vous devez acheter ou créer un outil d'annotation de données. De nombreux facteurs doivent être pris en compte et vous devez vous poser quelques questions pour comprendre vos besoins et savoir si vous devez réellement en acheter ou en construire un.
Pour simplifier les choses, voici quelques-uns des facteurs à prendre en compte.
Ton but
Le premier élément que vous devez définir est l'objectif avec vos concepts d'intelligence artificielle et d'apprentissage automatique.
- Pourquoi les implémentez-vous dans votre entreprise ?
- Résolvent-ils un problème réel auquel vos clients sont confrontés ?
- Font-ils un processus front-end ou backend ?
- Utiliserez-vous l'IA pour introduire de nouvelles fonctionnalités ou optimiser votre site Web, votre application ou un module existant ?
- Que fait votre concurrent dans votre segment ?
- Avez-vous suffisamment de cas d'utilisation nécessitant une intervention de l'IA ?
Les réponses à ces questions rassembleront vos pensées – qui peuvent actuellement être un peu partout – en un seul endroit et vous donneront plus de clarté.
Collecte de données d'IA / Licence
Les modèles d'IA ne nécessitent qu'un seul élément pour fonctionner : les données. Vous devez identifier d'où vous pouvez générer des volumes massifs de données de vérité terrain. Si votre entreprise génère de gros volumes de données qui doivent être traitées pour obtenir des informations cruciales sur l'entreprise, les opérations, la recherche sur les concurrents, l'analyse de la volatilité du marché, l'étude du comportement des clients, etc., vous avez besoin d'un outil d'annotation de données. Cependant, vous devez également tenir compte du volume de données que vous générez. Comme mentionné précédemment, un modèle d'IA n'est aussi efficace que la qualité et la quantité de données dont il est alimenté. Ainsi, vos décisions devraient invariablement dépendre de ce facteur.
Si vous ne disposez pas des bonnes données pour former vos modèles de ML, les fournisseurs peuvent vous être très utiles, en vous aidant à obtenir une licence de données du bon ensemble de données nécessaires pour former des modèles de ML. Dans certains cas, une partie de la valeur apportée par le fournisseur impliquera à la fois des prouesses techniques et également l'accès à des ressources qui favoriseront la réussite du projet.
Le budget
Une autre condition fondamentale qui influence probablement chaque facteur dont nous discutons actuellement. La solution à la question de savoir si vous devez créer ou acheter une annotation de données devient simple lorsque vous comprenez si vous avez suffisamment de budget à dépenser.
Complexités de conformité
 Les fournisseurs peuvent être extrêmement utiles en matière de confidentialité des données et de traitement correct des données sensibles. L'un de ces types de cas d'utilisation implique un hôpital ou une entreprise liée aux soins de santé qui souhaite utiliser la puissance de l'apprentissage automatique sans compromettre sa conformité à la HIPAA et à d'autres règles de confidentialité des données. Même en dehors du domaine médical, des lois comme le RGPD européen renforcent le contrôle des ensembles de données et exigent plus de vigilance de la part des parties prenantes des entreprises.
Les fournisseurs peuvent être extrêmement utiles en matière de confidentialité des données et de traitement correct des données sensibles. L'un de ces types de cas d'utilisation implique un hôpital ou une entreprise liée aux soins de santé qui souhaite utiliser la puissance de l'apprentissage automatique sans compromettre sa conformité à la HIPAA et à d'autres règles de confidentialité des données. Même en dehors du domaine médical, des lois comme le RGPD européen renforcent le contrôle des ensembles de données et exigent plus de vigilance de la part des parties prenantes des entreprises.
main-d'œuvre
L'annotation de données nécessite une main-d'œuvre qualifiée, quels que soient la taille, l'échelle et le domaine de votre entreprise. Même si vous générez un strict minimum de données chaque jour, vous avez besoin d'experts en données pour travailler sur vos données pour l'étiquetage. Alors, maintenant, vous devez savoir si vous disposez de la main-d'œuvre requise. Si c'est le cas, sont-ils qualifiés pour les outils et techniques requis ou ont-ils besoin d'être perfectionnés ? S'ils ont besoin d'être perfectionnés, avez-vous le budget pour les former en premier lieu ?
De plus, les meilleurs programmes d'annotation et d'étiquetage de données prennent un certain nombre d'experts en la matière ou dans un domaine et les segmentent en fonction de données démographiques telles que l'âge, le sexe et le domaine d'expertise - ou souvent en termes de langues localisées avec lesquelles ils travailleront. C'est, encore une fois, où nous, chez Shaip, parlons d'avoir les bonnes personnes aux bons sièges, conduisant ainsi les bons processus humains dans la boucle qui mèneront vos efforts programmatiques au succès.
Opérations de petits et grands projets et seuils de coûts
Dans de nombreux cas, le support fournisseur peut être une option pour un projet plus petit ou pour des phases de projet plus petites. Lorsque les coûts sont contrôlables, l'entreprise peut bénéficier de l'externalisation pour rendre les projets d'annotation ou d'étiquetage de données plus efficaces.
Les entreprises peuvent également examiner des seuils importants - où de nombreux fournisseurs lient le coût à la quantité de données consommées ou à d'autres références de ressources. Par exemple, disons qu'une entreprise s'est engagée auprès d'un fournisseur pour effectuer la saisie de données fastidieuse nécessaire à la configuration des ensembles de test.
Il peut y avoir un seuil caché dans l'accord où, par exemple, le partenaire commercial doit souscrire un autre bloc de stockage de données AWS, ou un autre composant de service d'Amazon Web Services, ou d'un autre fournisseur tiers. Ils répercutent cela sur le client sous la forme de coûts plus élevés, ce qui met le prix hors de portée du client.
Dans ces cas, mesurer les services que vous obtenez des fournisseurs aide à maintenir le projet abordable. La mise en place de la bonne portée garantira que les coûts du projet ne dépassent pas ce qui est raisonnable ou faisable pour l'entreprise en question.
Alternatives Open Source et Freeware
 Certaines alternatives au support complet des fournisseurs impliquent l'utilisation de logiciels open source, voire de logiciels gratuits, pour entreprendre des projets d'annotation ou d'étiquetage de données. Ici, il existe une sorte de terrain d'entente où les entreprises ne créent pas tout à partir de zéro, mais évitent également de trop dépendre des fournisseurs commerciaux.
Certaines alternatives au support complet des fournisseurs impliquent l'utilisation de logiciels open source, voire de logiciels gratuits, pour entreprendre des projets d'annotation ou d'étiquetage de données. Ici, il existe une sorte de terrain d'entente où les entreprises ne créent pas tout à partir de zéro, mais évitent également de trop dépendre des fournisseurs commerciaux.
La mentalité de bricolage de l'open source est elle-même une sorte de compromis - les ingénieurs et les personnes internes peuvent tirer parti de la communauté open source, où des bases d'utilisateurs décentralisées offrent leur propre type de support de base. Ce ne sera pas comme ce que vous obtenez d'un fournisseur – vous n'obtiendrez pas une assistance facile 24h/7 et XNUMXj/XNUMX ou des réponses aux questions sans faire de recherche interne – mais le prix est inférieur.
Alors, la grande question - Quand devriez-vous acheter un outil d'annotation de données :
Comme pour de nombreux types de projets de haute technologie, ce type d'analyse - quand construire et quand acheter - nécessite une réflexion et une prise en compte approfondies de la manière dont ces projets sont recherchés et gérés. Les défis auxquels la plupart des entreprises sont confrontées en ce qui concerne les projets d'IA/ML lorsqu'elles envisagent l'option « construire » ne concernent pas seulement les parties de construction et de développement du projet. Il y a souvent une énorme courbe d'apprentissage pour arriver au point où un véritable développement AI/ML peut se produire. Avec les nouvelles équipes et initiatives d'IA/ML, le nombre d'"inconnues inconnues" dépasse de loin le nombre d'"inconnues connues".
| Développer | Buy |
|---|---|
Avantages:
| Avantages:
|
Inconvénients:
| Inconvénients:
|
Pour rendre les choses encore plus simples, considérez les aspects suivants :
- lorsque vous travaillez sur d'énormes volumes de données
- lorsque vous travaillez sur diverses variétés de données
- lorsque les fonctionnalités associées à vos modèles ou solutions pourraient changer ou évoluer dans le futur
- lorsque vous avez un cas d'utilisation vague ou générique
- lorsque vous avez besoin d'une idée claire sur les dépenses impliquées dans le déploiement d'un outil d'annotation de données
- et lorsque vous n'avez pas la bonne main-d'œuvre ou des experts qualifiés pour travailler sur les outils et que vous recherchez une courbe d'apprentissage minimale
Si vos réponses étaient opposées à ces scénarios, vous devriez vous concentrer sur la création de votre outil.
Comment choisir le bon outil d'annotation de données pour votre projet
Si vous lisez ceci, ces idées semblent passionnantes et sont certainement plus faciles à dire qu'à faire. Alors, comment tirer parti de la pléthore d'outils d'annotation de données déjà existants ? Ainsi, la prochaine étape consiste à considérer les facteurs associés au choix du bon outil d'annotation de données.
Contrairement à il y a quelques années, le marché a évolué avec des tonnes d'outils d'annotation de données en pratique aujourd'hui. Les entreprises ont plus d'options pour en choisir un en fonction de leurs besoins distincts. Mais chaque outil est livré avec son propre ensemble d'avantages et d'inconvénients. Pour prendre une décision judicieuse, il faut également suivre une voie objective en dehors des exigences subjectives.
Examinons quelques-uns des facteurs cruciaux que vous devriez considérer dans le processus.
Définir votre cas d'utilisation
Pour sélectionner le bon outil d'annotation de données, vous devez définir votre cas d'utilisation. Vous devez savoir si votre besoin implique du texte, une image, une vidéo, de l'audio ou un mélange de tous les types de données. Il existe des outils autonomes que vous pouvez acheter et des outils holistiques qui vous permettent d'exécuter diverses actions sur des ensembles de données.
Les outils d'aujourd'hui sont intuitifs et vous offrent des options en termes d'installations de stockage (réseau, local ou cloud), de techniques d'annotation (audio, image, 3D…) et bien d'autres aspects. Vous pouvez choisir un outil en fonction de vos besoins spécifiques.
Établir des normes de contrôle de la qualité
 Il s'agit d'un facteur crucial à prendre en compte, car l'objectif et l'efficacité de vos modèles d'IA dépendent des normes de qualité que vous établissez. Comme un audit, vous devez effectuer des contrôles de qualité des données que vous alimentez et des résultats obtenus pour comprendre si vos modèles sont entraînés de la bonne manière et aux bonnes fins. Cependant, la question est de savoir comment comptez-vous établir des normes de qualité?
Il s'agit d'un facteur crucial à prendre en compte, car l'objectif et l'efficacité de vos modèles d'IA dépendent des normes de qualité que vous établissez. Comme un audit, vous devez effectuer des contrôles de qualité des données que vous alimentez et des résultats obtenus pour comprendre si vos modèles sont entraînés de la bonne manière et aux bonnes fins. Cependant, la question est de savoir comment comptez-vous établir des normes de qualité?
Comme pour de nombreux types de travaux, de nombreuses personnes peuvent effectuer une annotation et un balisage de données, mais elles le font avec divers degrés de réussite. Lorsque vous demandez un service, vous ne vérifiez pas automatiquement le niveau de contrôle qualité. C'est pourquoi les résultats varient.
Alors, voulez-vous déployer un modèle de consensus, où les annotateurs offrent un retour sur la qualité et des mesures correctives sont prises instantanément ? Ou préférez-vous l'examen d'échantillons, les étalons or ou l'intersection aux modèles syndicaux ?
Le meilleur plan d'achat garantira que le contrôle de la qualité est en place dès le début en établissant des normes avant que tout contrat final ne soit conclu. Lors de l'établissement de cela, vous ne devez pas non plus négliger les marges d'erreur. L'intervention manuelle ne peut pas être complètement évitée car les systèmes sont voués à produire des erreurs à des taux allant jusqu'à 3 %. Cela demande du travail en amont, mais cela en vaut la peine.
Qui annotera vos données ?
Le prochain facteur majeur dépend de la personne qui annote vos données. Avez-vous l'intention d'avoir une équipe en interne ou préférez-vous l'externaliser ? Si vous sous-traitez, vous devez prendre en compte des aspects juridiques et des mesures de conformité en raison des problèmes de confidentialité et de confidentialité associés aux données. Et si vous avez une équipe interne, dans quelle mesure est-elle efficace pour apprendre un nouvel outil ? Quel est votre délai de mise sur le marché avec votre produit ou service ? Avez-vous les bons indicateurs de qualité et les bonnes équipes pour approuver les résultats ?
Le vendeur vs. Débat des partenaires
 L'annotation des données est un processus collaboratif. Cela implique des dépendances et des complexités comme l'interopérabilité. Cela signifie que certaines équipes travaillent toujours en tandem et que l'une des équipes pourrait être votre fournisseur. C'est pourquoi le fournisseur ou le partenaire que vous sélectionnez est aussi important que l'outil que vous utilisez pour l'étiquetage des données.
L'annotation des données est un processus collaboratif. Cela implique des dépendances et des complexités comme l'interopérabilité. Cela signifie que certaines équipes travaillent toujours en tandem et que l'une des équipes pourrait être votre fournisseur. C'est pourquoi le fournisseur ou le partenaire que vous sélectionnez est aussi important que l'outil que vous utilisez pour l'étiquetage des données.
Avec ce facteur, des aspects tels que la capacité de garder vos données et intentions confidentielles, l'intention d'accepter et de travailler sur les commentaires, d'être proactif en termes de demandes de données, de flexibilité dans les opérations et plus encore doivent être pris en compte avant de serrer la main d'un fournisseur ou d'un partenaire. . Nous avons inclus la flexibilité car les exigences d'annotation des données ne sont pas toujours linéaires ou statiques. Ils pourraient changer à l'avenir à mesure que vous développerez votre entreprise. Si vous ne traitez actuellement que des données textuelles, vous souhaiterez peut-être annoter les données audio ou vidéo au fur et à mesure de votre mise à l'échelle et votre support devrait être prêt à élargir ses horizons avec vous.
Implication du fournisseur
L'un des moyens d'évaluer l'implication des fournisseurs est le soutien que vous recevrez.
Tout plan d'achat doit tenir compte de cet élément. A quoi ressemblera le soutien sur le terrain ? Qui seront les parties prenantes et les personnes-ressources des deux côtés de l'équation ?
Il existe également des tâches concrètes qui doivent préciser quelle est (ou sera) l'implication du vendeur. Pour un projet d'annotation ou d'étiquetage de données en particulier, le fournisseur fournira-t-il activement ou non les données brutes ? Qui agira en tant qu'experts en la matière et qui les emploiera soit en tant qu'employés, soit en tant qu'entrepreneurs indépendants ?
Études de cas
Voici quelques exemples d'études de cas spécifiques qui expliquent comment l'annotation et l'étiquetage des données fonctionnent réellement sur le terrain. Chez Shaip, nous veillons à fournir les plus hauts niveaux de qualité et des résultats supérieurs dans l'annotation et l'étiquetage des données.
Une grande partie de la discussion ci-dessus sur les réalisations standard pour l'annotation et l'étiquetage des données révèle comment nous abordons chaque projet et ce que nous offrons aux entreprises et aux parties prenantes avec lesquelles nous travaillons.
Documents d'étude de cas qui démontreront comment cela fonctionne :

Dans un projet de licence de données cliniques, l'équipe Shaip a traité plus de 6,000 XNUMX heures d'audio, supprimant toutes les informations de santé protégées (PHI) et laissant le contenu conforme à la HIPAA pour les modèles de reconnaissance vocale des soins de santé.
Dans ce type de cas, ce sont les critères et le classement des réalisations qui sont importants. Les données brutes sont sous forme d'audio, et il est nécessaire d'anonymiser les parties. Par exemple, en utilisant l'analyse NER, le double objectif est de dé-identifier et d'annoter le contenu.
Une autre étude de cas implique une étude approfondie données d'entraînement à l'IA conversationnelle projet que nous avons réalisé avec 3,000 14 linguistes travaillant sur une période de 27 semaines. Cela a conduit à la production de données de formation en XNUMX langues, afin de faire évoluer des assistants numériques multilingues capables de gérer les interactions humaines dans une large sélection de langues maternelles.
Dans cette étude de cas particulière, le besoin d'avoir la bonne personne dans la bonne chaise était évident. Le grand nombre d'experts en la matière et d'opérateurs de saisie de contenu signifiait qu'il était nécessaire de rationaliser l'organisation et les procédures pour mener à bien le projet dans un délai particulier. Notre équipe a été en mesure de surpasser largement la norme de l'industrie, en optimisant la collecte de données et les processus ultérieurs.
D'autres types d'études de cas impliquent des choses comme la formation de bots et l'annotation de texte pour l'apprentissage automatique. Encore une fois, dans un format texte, il est toujours important de traiter les parties identifiées conformément aux lois sur la confidentialité et de trier les données brutes pour obtenir les résultats ciblés.
En d'autres termes, en travaillant sur plusieurs types et formats de données, Shaip a démontré le même succès vital en appliquant les mêmes méthodes et principes à la fois aux données brutes et aux scénarios commerciaux de licence de données.