
Une solution robuste basée sur l'IA est construite sur des données - pas n'importe quelles données, mais des données de haute qualité et annotées avec précision. Seules les données les meilleures et les plus raffinées peuvent alimenter votre projet d'IA, et cette pureté des données aura un impact énorme sur le résultat du projet.
Nous avons souvent appelé les données le carburant des projets d'IA, mais pas n'importe quelles données. Si vous avez besoin de carburant pour fusée pour aider votre projet à décoller, vous ne pouvez pas mettre d'huile brute dans le réservoir. Au lieu de cela, les données (comme le carburant) doivent être soigneusement affinées pour garantir que seules les informations de la plus haute qualité alimentent votre projet. Ce processus de raffinement est appelé annotation de données, et il existe de nombreuses idées fausses persistantes à son sujet.
Définir la qualité des données de formation dans Annotation
Nous savons que la qualité des données fait une grande différence dans le résultat du projet d'IA. Certains des modèles de ML les meilleurs et les plus performants sont basés sur des ensembles de données détaillés et étiquetés avec précision.
Mais comment définissons-nous exactement la qualité dans une annotation ?
Quand on parle de annotation de données qualité, la précision, la fiabilité et la cohérence sont importantes. Un ensemble de données est dit exact s'il correspond à la vérité terrain et aux informations du monde réel.
La cohérence des données fait référence au niveau de précision maintenu dans l'ensemble de données. Cependant, la qualité d'un ensemble de données est plus précisément déterminée par le type de projet, ses exigences uniques et le résultat souhaité. Par conséquent, cela devrait être le critère pour déterminer l'étiquetage des données et la qualité des annotations.
Pourquoi est-il important de définir la qualité des données ?
Il est important de définir la qualité des données car elle agit comme un facteur global qui détermine la qualité du projet et le résultat.
- Des données de mauvaise qualité peuvent avoir un impact sur le produit et les stratégies commerciales.
- Un système d'apprentissage automatique est aussi bon que la qualité des données sur lesquelles il est formé.
- Des données de bonne qualité éliminent les retouches et les coûts qui y sont associés.
- Il aide les entreprises à prendre des décisions de projet éclairées et respecte la conformité réglementaire.
Comment mesurons-nous la qualité des données d'entraînement lors de la labellisation ?

Il existe plusieurs méthodes pour mesurer la qualité des données de formation, et la plupart d'entre elles commencent par créer d'abord une directive concrète d'annotation des données. Certaines des méthodes incluent:
Des benchmarks établis par des experts
Des référentiels de qualité ou annotation étalon-or Les méthodes sont les options d'assurance qualité les plus simples et les plus abordables qui servent de point de référence pour mesurer la qualité des résultats du projet. Il mesure les annotations de données par rapport au référentiel établi par les experts.
Alpha test de Cronbach
Le test alpha de Cronbach détermine la corrélation ou la cohérence entre les éléments de l'ensemble de données. La fiabilité du label et une plus grande précision peut être mesuré sur la base de la recherche.
Mesure du consensus
La mesure du consensus détermine le niveau d'accord entre les annotateurs machine ou humains. Un consensus doit généralement être atteint pour chaque élément et doit être arbitré en cas de désaccord.
Examen par le comité
Un groupe d'experts détermine généralement l'exactitude de l'étiquette en examinant les étiquettes de données. Parfois, une partie définie des étiquettes de données est généralement prise comme échantillon pour déterminer l'exactitude.
Révision Données d'entraînement Qualité
Les entreprises qui se lancent dans des projets d'IA sont pleinement convaincues de la puissance de l'automatisation, c'est pourquoi beaucoup continuent de penser que l'annotation automatique pilotée par l'IA sera plus rapide et plus précise que l'annotation manuelle. Pour l'instant, la réalité est qu'il faut des humains pour identifier et classer les données, car la précision est si importante. Les erreurs supplémentaires créées par l'étiquetage automatique nécessiteront des itérations supplémentaires pour améliorer la précision de l'algorithme, annulant ainsi tout gain de temps.
Une autre idée fausse - et qui contribue probablement à l'adoption de l'annotation automatique - est que les petites erreurs n'ont pas beaucoup d'effet sur les résultats. Même les plus petites erreurs peuvent produire des inexactitudes importantes en raison d'un phénomène appelé dérive de l'IA, où les incohérences dans les données d'entrée conduisent un algorithme dans une direction que les programmeurs n'ont jamais voulue.
La qualité des données de formation - les aspects de précision et de cohérence - sont constamment examinées pour répondre aux exigences uniques des projets. Un examen des données de formation est généralement effectué à l'aide de deux méthodes différentes -
Techniques annotées automatiquement
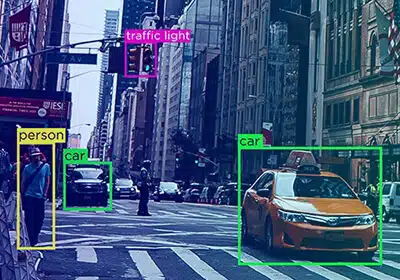 Le processus de révision automatique des annotations garantit que les commentaires sont réinjectés dans le système et évite les erreurs afin que les annotateurs puissent améliorer leurs processus.
Le processus de révision automatique des annotations garantit que les commentaires sont réinjectés dans le système et évite les erreurs afin que les annotateurs puissent améliorer leurs processus.
L'annotation automatique pilotée par l'intelligence artificielle est précise et plus rapide. L'annotation automatique réduit le temps passé par les AQ manuels à passer en revue, ce qui leur permet de consacrer plus de temps aux erreurs complexes et critiques dans l'ensemble de données. L'annotation automatique peut également aider à détecter les réponses non valides, les répétitions et les annotations incorrectes.
Manuellement via des experts en science des données
Les scientifiques des données examinent également les annotations des données pour garantir l'exactitude et la fiabilité de l'ensemble de données.
De petites erreurs et des inexactitudes d'annotation peuvent avoir un impact significatif sur le résultat du projet. Et ces erreurs peuvent ne pas être détectées par les outils de révision automatique des annotations. Les scientifiques des données effectuent des tests de qualité d'échantillons à partir de différentes tailles de lots pour détecter les incohérences de données et les erreurs involontaires dans l'ensemble de données.
Derrière chaque titre d'IA se cache un processus d'annotation, et Shaip peut aider à le rendre indolore
Éviter les pièges des projets d'IA
De nombreuses organisations souffrent d'un manque de ressources d'annotation internes. Les scientifiques et les ingénieurs des données sont très demandés, et embaucher suffisamment de ces professionnels pour entreprendre un projet d'IA signifie rédiger un chèque qui est hors de portée pour la plupart des entreprises. Au lieu de choisir une option budgétaire (telle que l'annotation de crowdsourcing) qui finira par vous hanter, envisagez de sous-traiter vos besoins d'annotation à un partenaire externe expérimenté. L'externalisation garantit un degré élevé de précision tout en réduisant les goulots d'étranglement liés à l'embauche, à la formation et à la gestion qui surviennent lorsque vous essayez de constituer une équipe interne.
Lorsque vous externalisez spécifiquement vos besoins d'annotation avec Shaip, vous puisez dans une force puissante qui peut accélérer votre initiative d'IA sans les raccourcis qui compromettront les résultats les plus importants. Nous offrons une main-d'œuvre entièrement gérée, ce qui signifie que vous pouvez obtenir une précision bien supérieure à celle que vous obtiendriez grâce aux efforts d'annotation de crowdsourcing. L'investissement initial peut être plus élevé, mais il sera rentable au cours du processus de développement lorsque moins d'itérations sont nécessaires pour obtenir le résultat souhaité.
Nos services de données couvrent également l'ensemble du processus, y compris l'approvisionnement, une capacité que la plupart des autres fournisseurs d'étiquetage ne peuvent pas offrir. Grâce à notre expérience, vous pouvez acquérir rapidement et facilement de gros volumes de données de haute qualité, géographiquement diverses, dépersonnalisées et conformes à toutes les réglementations pertinentes. Lorsque vous hébergez ces données dans notre plate-forme basée sur le cloud, vous avez également accès à des outils et des flux de travail éprouvés qui améliorent l'efficacité globale de votre projet et vous aident à progresser plus rapidement que vous ne le pensiez possible.
Et enfin, notre experts internes de l'industrie comprendre vos besoins uniques. Que vous construisiez un chatbot ou que vous travailliez à appliquer la technologie de reconnaissance faciale pour améliorer les soins de santé, nous sommes passés par là et pouvons vous aider à élaborer des directives qui garantiront que le processus d'annotation atteint les objectifs définis pour votre projet.
Chez Shaip, nous ne sommes pas seulement enthousiasmés par la nouvelle ère de l'IA. Nous l'aidons de manière incroyable, et notre expérience nous a aidés à lancer d'innombrables projets réussis. Pour voir ce que nous pouvons faire pour votre propre mise en œuvre, contactez-nous pour demander une démo dès aujourd’hui.


