

Que sont les grands modèles de langage ?
Les grands modèles de langage (LLM) sont des systèmes avancés d'intelligence artificielle (IA) conçus pour traiter, comprendre et générer du texte de type humain. Ils sont basés sur des techniques d'apprentissage en profondeur et formés sur des ensembles de données massifs, contenant généralement des milliards de mots provenant de diverses sources telles que des sites Web, des livres et des articles. Cette formation approfondie permet aux LLM de saisir les nuances de la langue, de la grammaire, du contexte et même de certains aspects des connaissances générales.
Certains LLM populaires, comme le GPT-3 d'OpenAI, utilisent un type de réseau neuronal appelé transformateur, qui leur permet de gérer des tâches linguistiques complexes avec une compétence remarquable. Ces modèles peuvent effectuer un large éventail de tâches, telles que :
- Répondre à des questions
- Résumé du texte
- Traduire des langues
- Génération de contenu
- Même s'engager dans des conversations interactives avec les utilisateurs
À mesure que les LLM continuent d'évoluer, ils offrent un grand potentiel pour améliorer et automatiser diverses applications dans tous les secteurs, du service client et de la création de contenu à l'éducation et à la recherche. Cependant, ils soulèvent également des préoccupations éthiques et sociétales, telles que les comportements biaisés ou les abus, qui doivent être résolues à mesure que la technologie progresse.

Exemples populaires de grands modèles de langage
Voici quelques exemples importants de LLM largement utilisés dans différents secteurs verticaux :
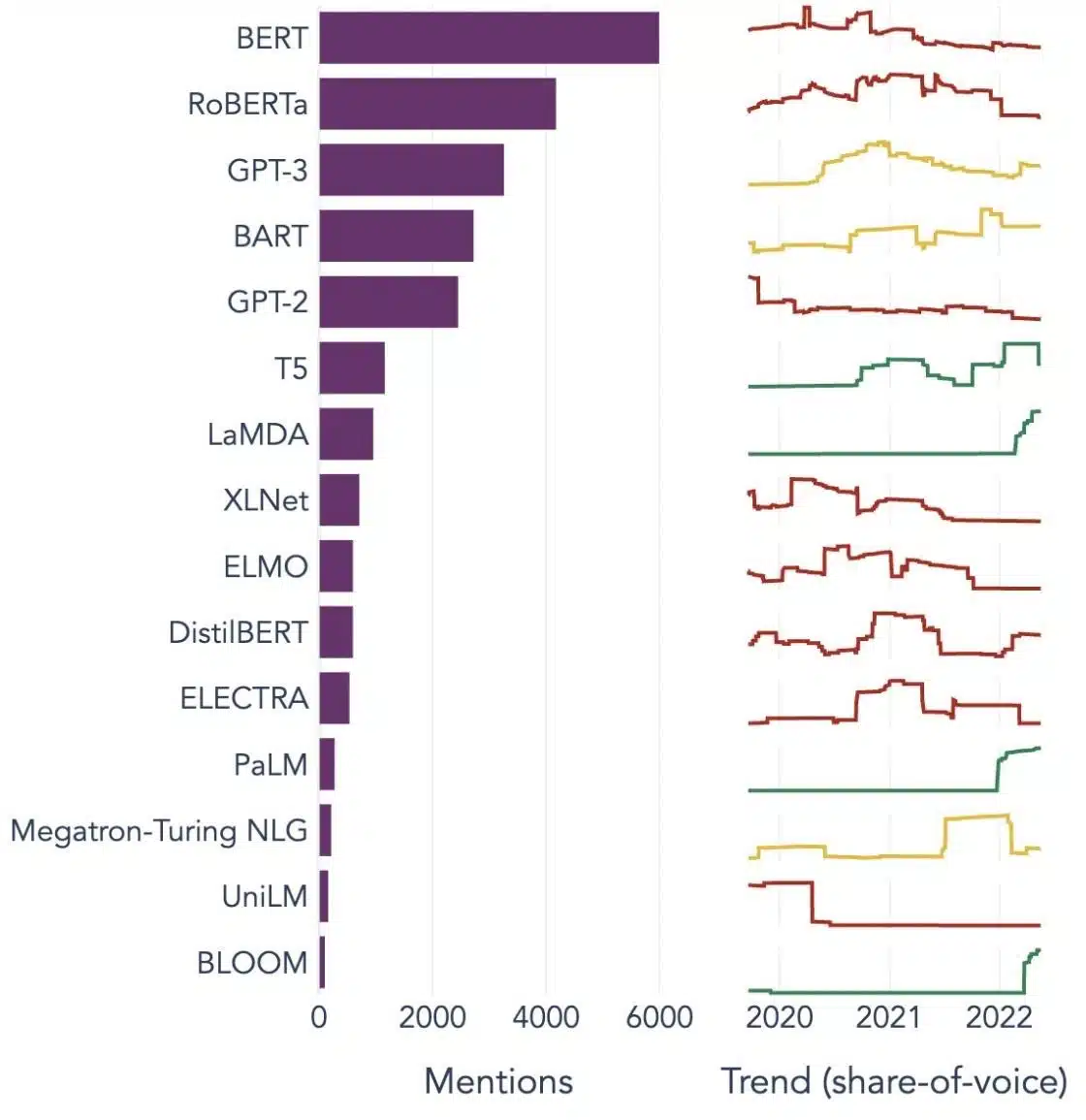
Source de l'image: Vers la science des données
Comment les modèles LLM sont-ils formés ?
La formation de grands modèles linguistiques (LLM) est tout un exploit qui implique plusieurs étapes cruciales. Voici un aperçu simplifié, étape par étape, du processus :
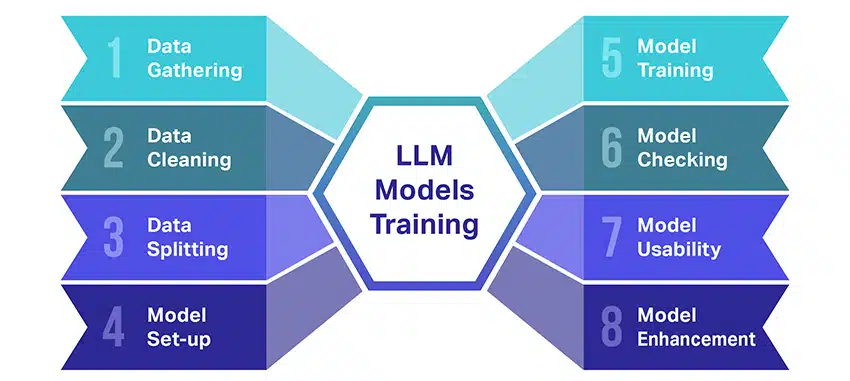
- Collecte de données textuelles : La formation d'un LLM commence par la collecte d'une grande quantité de données textuelles. Ces données peuvent provenir de livres, de sites Web, d'articles ou de plateformes de médias sociaux. L'objectif est de saisir la riche diversité du langage humain.
- Nettoyer les données : Les données textuelles brutes sont ensuite rangées dans un processus appelé prétraitement. Cela inclut des tâches telles que la suppression des caractères indésirables, la décomposition du texte en parties plus petites appelées jetons et la mise en forme du tout dans un format avec lequel le modèle peut fonctionner.
- Fractionner les données : Ensuite, les données propres sont divisées en deux ensembles. Un ensemble, les données d'entraînement, sera utilisé pour entraîner le modèle. L'autre ensemble, les données de validation, sera utilisé plus tard pour tester les performances du modèle.
- Configuration du modèle : La structure du LLM, appelée architecture, est alors définie. Cela implique de sélectionner le type de réseau de neurones et de décider de divers paramètres, tels que le nombre de couches et d'unités cachées au sein du réseau.
- Entraînement du modèle : La formation proprement dite commence maintenant. Le modèle LLM apprend en examinant les données de formation, en faisant des prédictions basées sur ce qu'il a appris jusqu'à présent, puis en ajustant ses paramètres internes pour réduire la différence entre ses prédictions et les données réelles.
- Vérification du modèle: L'apprentissage du modèle LLM est vérifié à l'aide des données de validation. Cela permet de voir les performances du modèle et d'ajuster les paramètres du modèle pour de meilleures performances.
- Utilisation du modèle: Après formation et évaluation, le modèle LLM est prêt à l'emploi. Il peut maintenant être intégré dans des applications ou des systèmes où il générera du texte basé sur les nouvelles entrées qui lui sont données.
- Amélioration du modèle : Enfin, il y a toujours place à l'amélioration. Le modèle LLM peut être affiné au fil du temps, en utilisant des données mises à jour ou en ajustant les paramètres en fonction des commentaires et de l'utilisation dans le monde réel.
N'oubliez pas que ce processus nécessite des ressources de calcul importantes, telles que des unités de traitement puissantes et un stockage important, ainsi que des connaissances spécialisées en apprentissage automatique. C'est pourquoi elle est généralement effectuée par des organismes de recherche spécialisés ou des entreprises ayant accès à l'infrastructure et à l'expertise nécessaires.
Le LLM repose-t-il sur un apprentissage supervisé ou non supervisé?
Les grands modèles de langage sont généralement entraînés à l'aide d'une méthode appelée apprentissage supervisé. En termes simples, cela signifie qu'ils apprennent à partir d'exemples qui leur montrent les bonnes réponses.
 Imaginez que vous apprenez des mots à un enfant en lui montrant des images. Vous leur montrez l'image d'un chat et dites « chat », et ils apprennent à associer cette image au mot. C'est ainsi que fonctionne l'apprentissage supervisé. Le modèle reçoit beaucoup de texte (les « images ») et les sorties correspondantes (les « mots »), et il apprend à les faire correspondre.
Imaginez que vous apprenez des mots à un enfant en lui montrant des images. Vous leur montrez l'image d'un chat et dites « chat », et ils apprennent à associer cette image au mot. C'est ainsi que fonctionne l'apprentissage supervisé. Le modèle reçoit beaucoup de texte (les « images ») et les sorties correspondantes (les « mots »), et il apprend à les faire correspondre.
Ainsi, si vous donnez une phrase à un LLM, il essaie de prédire le mot ou la phrase suivante en fonction de ce qu'il a appris des exemples. De cette façon, il apprend à générer un texte qui a du sens et s'adapte au contexte.
Cela dit, parfois, les LLM utilisent également un peu d'apprentissage non supervisé. C'est comme laisser l'enfant explorer une pièce pleine de jouets différents et apprendre à les connaître par lui-même. Le modèle examine les données non étiquetées, les modèles d'apprentissage et les structures sans se voir dire les «bonnes» réponses.
L'apprentissage supervisé utilise des données étiquetées avec des entrées et des sorties, contrairement à l'apprentissage non supervisé, qui n'utilise pas de données de sortie étiquetées.
En un mot, les LLM sont principalement formés à l'aide d'un apprentissage supervisé, mais ils peuvent également utiliser un apprentissage non supervisé pour améliorer leurs capacités, par exemple pour l'analyse exploratoire et la réduction de la dimensionnalité.
Quel est le volume de données (en Go) nécessaire pour former un grand modèle de langage ?
Le monde des possibilités pour la reconnaissance des données vocales et les applications vocales est immense, et elles sont utilisées dans plusieurs industries pour une pléthore d'applications.
La formation d'un grand modèle de langage n'est pas un processus unique, en particulier en ce qui concerne les données nécessaires. Cela dépend d'un tas de choses :
- La conception du modèle.
- Quel travail doit-il faire?
- Le type de données que vous utilisez.
- À quel point voulez-vous qu'il fonctionne ?
Cela dit, la formation des LLM nécessite généralement une quantité massive de données textuelles. Mais de quelle masse parle-t-on ? Eh bien, pensez bien au-delà des gigaoctets (Go). Nous examinons généralement des téraoctets (To) ou même des pétaoctets (Po) de données.
Considérez GPT-3, l'un des plus grands LLM du moment. Il est formé sur 570 Go de données texte. Les LLM plus petits peuvent avoir besoin de moins - peut-être 10-20 Go ou même 1 Go de gigaoctets - mais c'est quand même beaucoup.

Mais il ne s'agit pas seulement de la taille des données. La qualité compte aussi. Les données doivent être propres et variées pour aider le modèle à apprendre efficacement. Et vous ne pouvez pas oublier les autres pièces clés du puzzle, comme la puissance de calcul dont vous avez besoin, les algorithmes que vous utilisez pour la formation et la configuration matérielle dont vous disposez. Tous ces facteurs jouent un rôle important dans la formation d'un LLM.
L'essor des grands modèles de langage : pourquoi ils sont importants
Les LLM ne sont plus seulement un concept ou une expérience. Ils jouent de plus en plus un rôle essentiel dans notre paysage numérique. Mais pourquoi cela se produit-il ? Qu'est-ce qui rend ces LLM si importants? Examinons quelques facteurs clés.
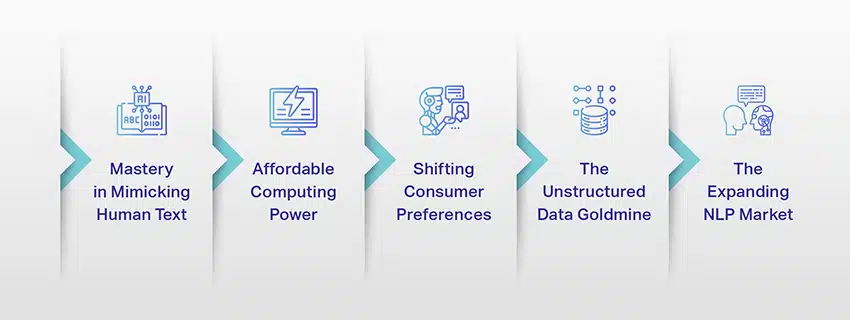
Maîtrise de l'imitation de texte humain
Les LLM ont transformé la façon dont nous gérons les tâches linguistiques. Construits à l'aide d'algorithmes d'apprentissage automatique robustes, ces modèles sont dotés de la capacité de comprendre les nuances du langage humain, y compris le contexte, l'émotion et même le sarcasme, dans une certaine mesure. Cette capacité à imiter le langage humain n'est pas une simple nouveauté, elle a des implications importantes.
Les capacités avancées de génération de texte des LLM peuvent tout améliorer, de la création de contenu aux interactions avec le service client.
Imaginez pouvoir poser à un assistant numérique une question complexe et obtenir une réponse non seulement logique, mais également cohérente, pertinente et livrée sur un ton conversationnel. C'est ce que permettent les LLM. Ils alimentent une interaction homme-machine plus intuitive et engageante, enrichissent les expériences utilisateur et démocratisent l'accès à l'information.
Puissance de calcul abordable
L'essor des LLM n'aurait pas été possible sans des développements parallèles dans le domaine de l'informatique. Plus précisément, la démocratisation des ressources informatiques a joué un rôle important dans l'évolution et l'adoption des LLM.
Les plates-formes basées sur le cloud offrent un accès sans précédent à des ressources informatiques hautes performances. De cette façon, même les petites organisations et les chercheurs indépendants peuvent former des modèles d'apprentissage automatique sophistiqués.
De plus, les améliorations des unités de traitement (comme les GPU et les TPU), combinées à l'essor de l'informatique distribuée, ont rendu possible l'entraînement de modèles avec des milliards de paramètres. Cette accessibilité accrue de la puissance de calcul permet la croissance et le succès des LLM, conduisant à plus d'innovation et d'applications dans le domaine.
Changer les préférences des consommateurs
Les consommateurs d'aujourd'hui ne veulent pas seulement des réponses ; ils veulent des interactions engageantes et pertinentes. À mesure que de plus en plus de personnes grandissent en utilisant la technologie numérique, il est évident que le besoin d'une technologie qui semble plus naturelle et plus humaine augmente. Les LLM offrent une opportunité inégalée de répondre à ces attentes. En générant un texte de type humain, ces modèles peuvent créer des expériences numériques attrayantes et dynamiques, ce qui peut accroître la satisfaction et la fidélité des utilisateurs. Qu'il s'agisse de chatbots IA fournissant un service client ou d'assistants vocaux fournissant des mises à jour, les LLM inaugurent une ère d'IA qui nous comprend mieux.
La mine d'or des données non structurées
Les données non structurées, telles que les e-mails, les publications sur les réseaux sociaux et les avis des clients, sont une mine d'informations. On estime que plus 80% des données d'entreprise ne sont pas structurées et croissent à un rythme 55% par an. Ces données sont une mine d'or pour les entreprises si elles sont exploitées correctement.
Les LLM entrent en jeu ici, avec leur capacité à traiter et à donner un sens à ces données à grande échelle. Ils peuvent gérer des tâches telles que l'analyse des sentiments, la classification de texte, l'extraction d'informations, etc., fournissant ainsi des informations précieuses.
Qu'il s'agisse d'identifier les tendances à partir des publications sur les réseaux sociaux ou d'évaluer le sentiment des clients à partir des avis, les LLM aident les entreprises à naviguer dans la grande quantité de données non structurées et à prendre des décisions basées sur les données.
Le marché en expansion de la PNL
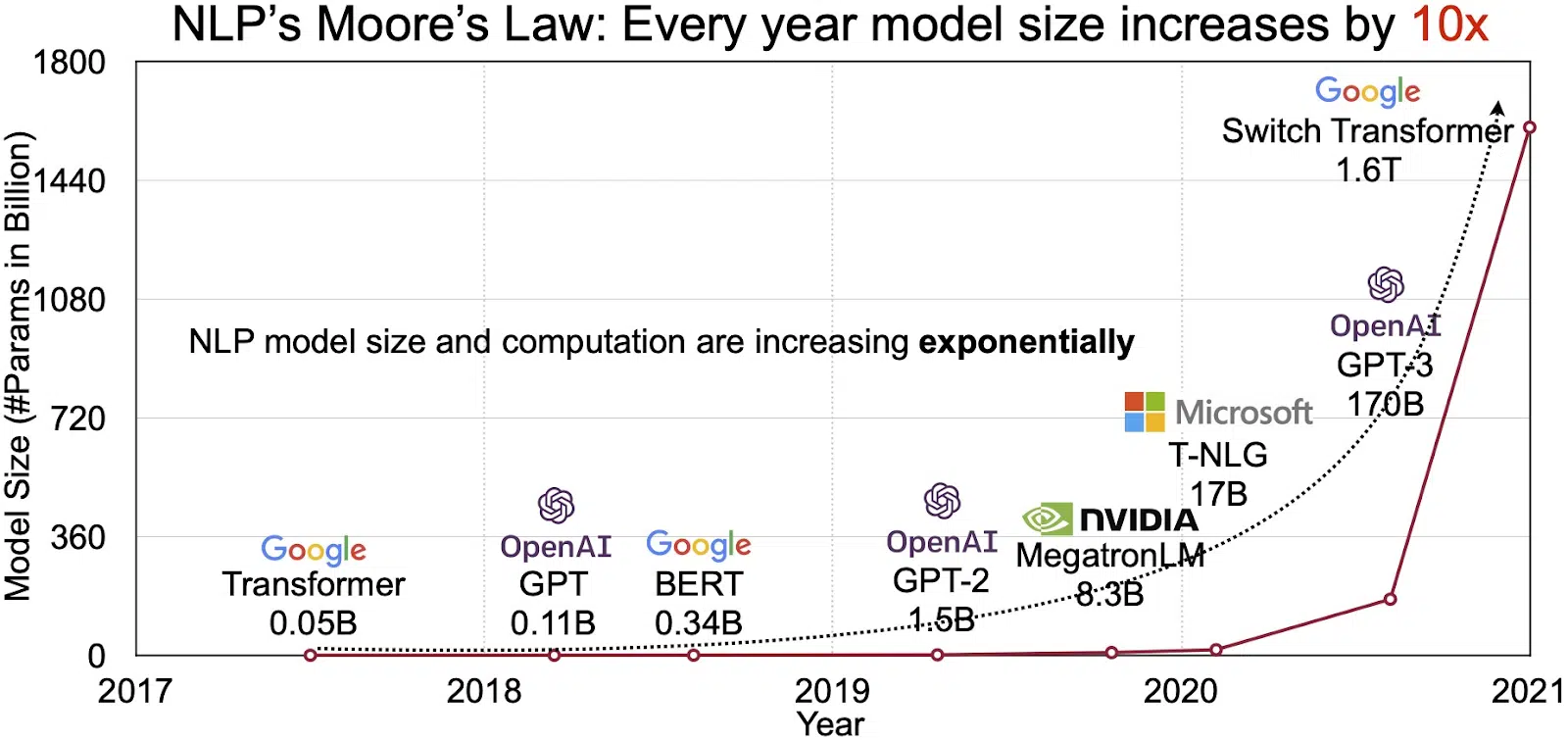
Le potentiel des LLM se reflète dans le marché en croissance rapide du traitement du langage naturel (TAL). Les analystes prévoient que le marché de la PNL passera de 11 milliards de dollars en 2020 à plus de 35 milliards de dollars d'ici 2026. Mais ce n'est pas seulement la taille du marché qui s'étend. Les modèles eux-mêmes se développent également, à la fois en taille physique et en nombre de paramètres qu'ils gèrent. L'évolution des LLM au fil des ans, comme le montre la figure ci-dessous (source de l'image : lien), souligne leur complexité et leur capacité croissantes.
Cas d'utilisation populaires des grands modèles de langage
Voici quelques-uns des cas d'utilisation les plus courants et les plus répandus de LLM :
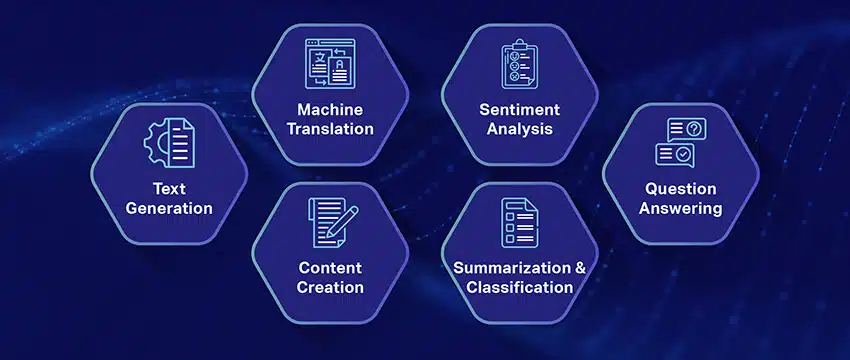
- Génération de texte en langage naturel : Les grands modèles de langage (LLM) combinent la puissance de l'intelligence artificielle et de la linguistique computationnelle pour produire de manière autonome des textes en langage naturel. Ils peuvent répondre à divers besoins des utilisateurs, tels que rédiger des articles, créer des chansons ou engager des conversations avec les utilisateurs.
- Traduction par les machines : Les LLM peuvent être utilisés efficacement pour traduire du texte entre n'importe quelle paire de langues. Ces modèles exploitent des algorithmes d'apprentissage en profondeur comme les réseaux de neurones récurrents pour comprendre la structure linguistique des langues source et cible, facilitant ainsi la traduction du texte source dans la langue souhaitée.
- Créer du contenu original : Les LLM ont ouvert la voie aux machines pour générer un contenu cohérent et logique. Ce contenu peut être utilisé pour créer des articles de blog, des articles et d'autres types de contenu. Les modèles puisent dans leur profonde expérience d'apprentissage en profondeur pour formater et structurer le contenu d'une manière nouvelle et conviviale.
- Analyser les sentiments : Une application intrigante des grands modèles de langage est l'analyse des sentiments. En cela, le modèle est formé pour reconnaître et catégoriser les états émotionnels et les sentiments présents dans le texte annoté. Le logiciel peut identifier des émotions telles que la positivité, la négativité, la neutralité et d'autres sentiments complexes. Cela peut fournir des informations précieuses sur les commentaires et les opinions des clients sur divers produits et services.
- Comprendre, résumer et classer un texte : Les LLM établissent une structure viable pour que les logiciels d'IA interprètent le texte et son contexte. En demandant au modèle de comprendre et d'examiner de grandes quantités de données, les LLM permettent aux modèles d'IA de comprendre, de résumer et même de catégoriser le texte sous diverses formes et modèles.
- Répondre à des questions: Les grands modèles de langage équipent les systèmes de réponse aux questions (QA) de la capacité de percevoir et de répondre avec précision à la requête en langage naturel d'un utilisateur. Des exemples populaires de ce cas d'utilisation incluent ChatGPT et BERT, qui examinent le contexte d'une requête et passent au crible une vaste collection de textes pour fournir des réponses pertinentes aux questions des utilisateurs.

Balisage de la partie du discours (POS)
Les mots dans les phrases sont étiquetés avec leur fonction grammaticale, comme les verbes, les noms, les adjectifs, etc. Ce processus aide le modèle à comprendre la grammaire et les liens entre les mots.

Reconnaissance des entités nommées (NER)
Les entités nommées telles que les organisations, les lieux et les personnes dans une phrase sont marquées. Cet exercice aide le modèle à interpréter les significations sémantiques des mots et des phrases et fournit des réponses plus précises.

Analyse des sentiments
Les données textuelles se voient attribuer des étiquettes de sentiment telles que positif, neutre ou négatif, aidant le modèle à saisir la nuance émotionnelle des phrases. Il est particulièrement utile pour répondre aux requêtes impliquant des émotions et des opinions.
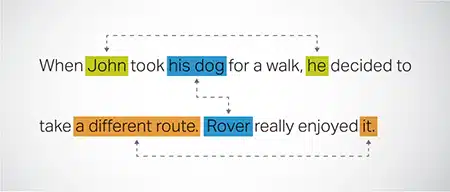
Résolution de coréférence
Identifier et résoudre les cas où la même entité est mentionnée dans différentes parties d'un texte. Cette étape aide le modèle à comprendre le contexte de la phrase, conduisant ainsi à des réponses cohérentes.
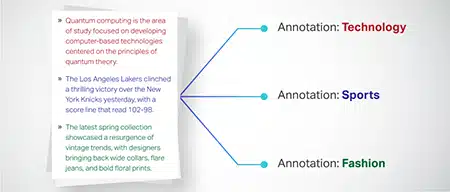
Classification du texte
Les données textuelles sont classées dans des groupes prédéfinis, tels que des critiques de produits ou des articles de presse. Cela aide le modèle à discerner le genre ou le sujet du texte, générant des réponses plus pertinentes.
Offrande de Shaip
Shai offre une large gamme de services pour aider les organisations à gérer, analyser et tirer le meilleur parti de leurs données.
Web-scraping de données
L'un des services clés offerts par Shaip est le grattage des données. Cela implique l'extraction de données à partir d'URL spécifiques à un domaine. En utilisant des outils et des techniques automatisés, Shaip peut rapidement et efficacement récupérer de gros volumes de données à partir de divers sites Web, manuels de produits, documentation technique, forums en ligne, avis en ligne, données du service client, documents réglementaires de l'industrie, etc. Ce processus peut être inestimable pour les entreprises lorsque la collecte de données pertinentes et spécifiques à partir d'une multitude de sources.

Traduction automatique
Développez des modèles à l'aide de vastes ensembles de données multilingues associés aux transcriptions correspondantes pour la traduction de texte dans différentes langues. Ce processus permet de démanteler les barrières linguistiques et favorise l'accessibilité de l'information.
Extraction et création de taxonomie
Shaip peut aider à l'extraction et à la création de taxonomie. Cela implique de classer et de catégoriser les données dans un format structuré qui reflète les relations entre les différents points de données. Cela peut être particulièrement utile pour les entreprises dans l'organisation de leurs données, les rendant plus accessibles et plus faciles à analyser. Par exemple, dans une entreprise de commerce électronique, les données sur les produits peuvent être classées en fonction du type de produit, de la marque, du prix, etc., ce qui facilite la navigation des clients dans le catalogue de produits.
Collecte des Données
Nos services de collecte de données fournissent des données critiques du monde réel ou synthétiques nécessaires à la formation d'algorithmes d'IA générative et à l'amélioration de la précision et de l'efficacité de vos modèles. Les données sont impartiales, obtenues de manière éthique et responsable tout en gardant à l'esprit la confidentialité et la sécurité des données.

Questions et réponses
La réponse aux questions (QA) est un sous-domaine du traitement du langage naturel axé sur la réponse automatique aux questions en langage humain. Les systèmes d'assurance qualité sont formés sur du texte et du code étendus, ce qui leur permet de traiter divers types de questions, y compris des questions factuelles, définitionnelles et basées sur des opinions. La connaissance du domaine est cruciale pour développer des modèles d'assurance qualité adaptés à des domaines spécifiques tels que le support client, la santé ou la chaîne d'approvisionnement. Cependant, les approches d'AQ génératives permettent aux modèles de générer du texte sans connaissance du domaine, en s'appuyant uniquement sur le contexte.
Notre équipe de spécialistes peut étudier méticuleusement des documents ou des manuels complets pour générer des paires Question-Réponse, facilitant la création d'IA générative pour les entreprises. Cette approche peut répondre efficacement aux demandes des utilisateurs en extrayant des informations pertinentes à partir d'un vaste corpus. Nos experts certifiés assurent la production de paires de questions-réponses de qualité supérieure couvrant divers sujets et domaines.

Synthèse de texte
Nos spécialistes sont capables de distiller des conversations complètes ou de longs dialogues, en fournissant des résumés succincts et perspicaces à partir de données textuelles étendues.

Génération de texte
Entraînez des modèles à l'aide d'un large ensemble de données de texte dans divers styles, comme des articles de presse, de la fiction et de la poésie. Ces modèles peuvent ensuite générer divers types de contenu, y compris des articles d'actualité, des entrées de blog ou des publications sur les réseaux sociaux, offrant une solution rentable et rapide pour la création de contenu.
Reconnaissance vocale
Développer des modèles capables de comprendre le langage parlé pour diverses applications. Cela inclut les assistants à commande vocale, les logiciels de dictée et les outils de traduction en temps réel. Le processus implique l'utilisation d'un ensemble de données complet composé d'enregistrements audio de la langue parlée, associés à leurs transcriptions correspondantes.

Recommandations de produits
Développez des modèles à l'aide de vastes ensembles de données sur les historiques d'achat des clients, y compris des étiquettes indiquant les produits que les clients sont enclins à acheter. L'objectif est de fournir des suggestions précises aux clients, ce qui stimule les ventes et améliore la satisfaction des clients.
Sous-titrage d'images
Révolutionnez votre processus d'interprétation d'images avec notre service de pointe de sous-titrage d'images basé sur l'IA. Nous insufflons de la vitalité aux images en produisant des descriptions précises et contextuellement significatives. Cela ouvre la voie à des possibilités innovantes d'engagement et d'interaction avec votre contenu visuel pour votre public.

Services de synthèse vocale
Nous fournissons un vaste ensemble de données composé d'enregistrements audio de la parole humaine, idéal pour la formation de modèles d'IA. Ces modèles sont capables de générer des voix naturelles et engageantes pour vos applications, offrant ainsi une expérience sonore distinctive et immersive à vos utilisateurs.



