



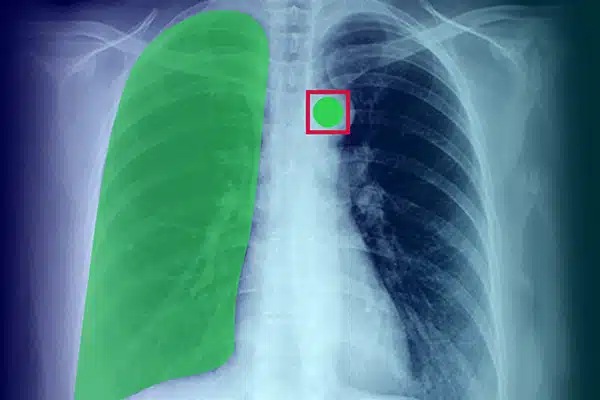
Image Annotation
Améliorez l’IA médicale en annotant les données visuelles des radiographies, des tomodensitogrammes et des IRM. Assurez-vous que les modèles d’IA fonctionnent parfaitement en matière de diagnostic et de traitement, guidés par un étiquetage de données expert. Obtenez de meilleurs résultats pour les patients grâce à des informations d’imagerie supérieures.
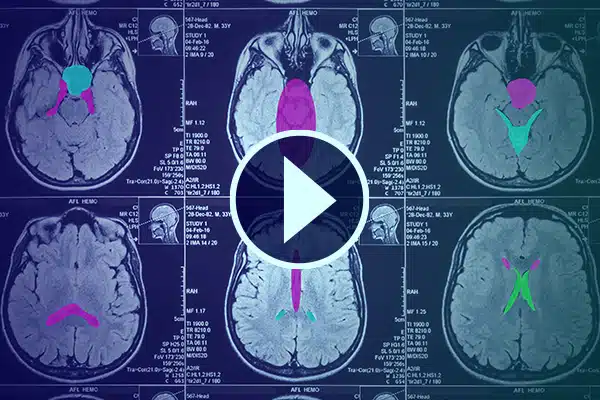
Annotation vidéo
Faites progresser l’IA dans le domaine de la santé grâce à des annotations vidéo détaillées. Affinez l’apprentissage de l’IA avec des classifications et des segmentations dans les images médicales. Améliorez votre IA chirurgicale et la surveillance des patients pour améliorer la prestation des soins de santé et les diagnostics.
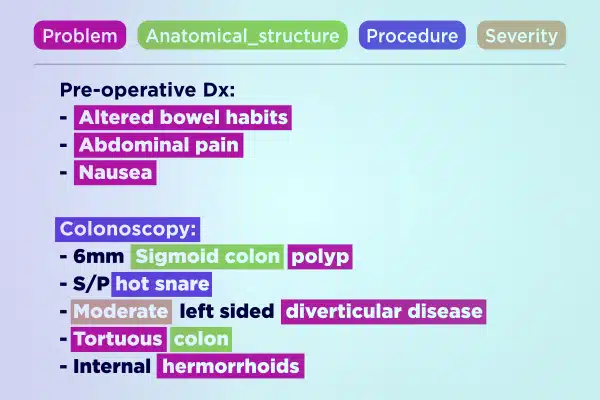
Annotation textuelle
Rationalisez le développement de l’IA médicale avec des données textuelles annotées par des experts. Analysez et enrichissez rapidement de vastes volumes de texte, des notes manuscrites aux rapports d'assurance. Garantissez des informations précises et exploitables sur les progrès des soins de santé.

Annotation audio
Tirez parti de l’expertise en PNL pour annoter et étiqueter avec précision les données audio médicales. Créez des systèmes à assistance vocale pour des opérations cliniques transparentes et intégrez l’IA dans divers produits de santé à commande vocale. Améliorez la précision du diagnostic grâce à une conservation experte des données audio.

Codage médical
Rationalisez la documentation médicale en la convertissant en codes universels grâce au codage médical IA. Garantissez l’exactitude, améliorez l’efficacité de la facturation et soutenez une prestation transparente de services de santé grâce à une assistance de pointe par l’IA pour le codage des dossiers médicaux.

Phase 1: Expertise technique du domaine (comprendre la portée et les directives d'annotation)

Phase 2: Former les ressources adaptées au projet

Phase 3: Cycle de feedback et QA des documents annotés
Radiologie
Notre service d’annotation d’images radiologiques affine les diagnostics d’IA et inclut une couche d’expertise supplémentaire. Chaque radiographie, IRM et tomodensitométrie est méticuleusement étiquetée et examinée par un expert en la matière. Cette étape supplémentaire dans la formation et la révision renforce la capacité de l'IA à détecter les anomalies et les maladies. Cela améliore la précision avant la livraison à nos clients.

Cardiologie
Notre annotation d’images axée sur la cardiologie affine les diagnostics de l’IA. Nous faisons appel à des experts en cardiologie qui étiquetent les images cardiaques complexes et forment nos modèles d’IA. Avant d'envoyer des données aux clients, ces spécialistes examinent chaque image pour garantir une précision optimale. Ce processus permet à l’IA de détecter plus précisément les maladies cardiaques.
#
Notre service d’annotation d’images en dentisterie étiquette les images dentaires pour améliorer les outils de diagnostic de l’IA. En identifiant avec précision la carie dentaire, les problèmes d'alignement et d'autres problèmes dentaires, nos PME permettent à l'IA d'améliorer les résultats pour les patients et d'aider les dentistes à planifier un traitement précis et à détecter précocement.


















Personnes
Des équipes dédiées et formées:
- Plus de 30,000 collaborateurs pour la création de données, l'étiquetage et le contrôle qualité
- Équipe de gestion de projet accréditée
- Équipe de développement de produits expérimentée
- Équipe d'approvisionnement et d'intégration du pool de talents

Processus
Une efficacité de processus maximale est assurée avec:
- Processus robuste 6 Sigma Stage-Gate
- Une équipe dédiée de ceintures noires 6 Sigma – Responsables des processus clés & Conformité qualité
- Amélioration continue et boucle de rétroaction

Plateforme
La plateforme brevetée offre des avantages :
- Plateforme Web de bout en bout
- Une qualité irréprochable
- TAT plus rapide
- Livraison transparente



