
La clé pour surmonter les obstacles au développement de l'IA : des données plus fiables
Aujourd'hui, la personne moyenne a maintenant des millions de fois plus de puissance de calcul dans sa poche que la NASA n'en avait pour réussir l'alunissage en 1969. Ce même appareil omniprésent qui démontre commodément une abondance de puissance de calcul remplit également une autre condition préalable à l'âge d'or de l'IA : une abondance de données. Selon les informations de l'Information Overload Research Group, 90 % des données mondiales ont été créées au cours des deux dernières années. Maintenant que la croissance exponentielle de la puissance de calcul a finalement convergé avec une croissance tout aussi fulgurante de la génération de données, les innovations en matière de données d'IA explosent tellement que certains experts pensent qu'elles déclencheront une quatrième révolution industrielle.
Les données de la National Venture Capital Association indiquent que le secteur de l'IA a enregistré un investissement record de 6.9 milliards de dollars au premier trimestre 2020. Il n'est pas difficile de voir le potentiel des outils d'IA car il est déjà exploité tout autour de nous. Certains des cas d'utilisation les plus visibles des produits d'IA sont les moteurs de recommandation derrière nos applications préférées telles que Spotify et Netflix. Bien qu'il soit amusant de découvrir un nouvel artiste à écouter ou une nouvelle émission de télévision à regarder en rafale, ces implémentations sont plutôt à faible enjeu. D'autres algorithmes notent les résultats des tests - déterminant en partie où les étudiants sont acceptés à l'université - et d'autres encore passent au crible les curriculum vitae des candidats, décidant quels candidats obtiennent un emploi particulier. Certains outils d'IA peuvent même avoir des implications de vie ou de mort, comme le modèle d'IA qui dépiste le cancer du sein (qui surpasse les médecins).
Malgré une croissance constante des exemples concrets de développement de l'IA et du nombre de startups en lice pour créer la prochaine génération d'outils de transformation, des défis pour un développement et une mise en œuvre efficaces demeurent. En particulier, la sortie de l'IA est aussi précise que l'entrée le permet, ce qui signifie que la qualité est primordiale.

Naviguer dans des demandes de conformité complexes
Comme si trouver des données de qualité n'était pas assez difficile, certaines des industries qui ont le plus à gagner des innovations en matière de données d'IA sont également les plus réglementées. Les soins de santé en sont peut-être le meilleur exemple, et bien qu'une enquête de HIT Infrastructure ait révélé que 91 % des initiés de l'industrie pensent que la technologie pourrait améliorer l'accès aux soins, cet optimisme est tempéré par le fait que 75 % la considèrent comme une menace pour la sécurité et la vie privée des patients. – et les patients ne sont pas les seuls à risque.
Les réglementations radicales promulguées par le biais de la loi sur la portabilité et la responsabilité en matière d'assurance maladie croisent désormais divers obstacles locaux à la conformité des données, tels que le règlement général européen sur la protection des données, le California Consumer Privacy Act aux États-Unis et le Personal Data Protection Act à Singapour. Ces réglementations locales seront rejointes par beaucoup d'autres, et à mesure que la télésanté apparaît comme une source plus importante de données sur la santé, il est probable que les réglementations aient une emprise encore plus stricte sur les données des patients en transit. En conséquence, la plate-forme cloud sécurisée et conforme de Shaip s'avérera être un moyen encore plus précieux d'amasser et d'accéder aux données de santé pour former des produits d'IA.
Les informations personnellement identifiables peuvent constituer une menace importante pour le développement de votre IA, mais même une implémentation totalement conforme est menacée si elle ne peut pas fournir le type de résultats précis qui ne viennent qu'avec diverses données de formation. Une étude de 2020 dans le Journal of the American Medical Association a démontré que les algorithmes d'apprentissage automatique dans le domaine médical sont le plus souvent formés avec des données de patients en Californie, à New York et au Massachusetts. Étant donné que ces patients représentent moins d'un cinquième de la population américaine, sans parler du reste du monde, il est difficile d'imaginer comment ces modèles pourraient produire autre chose que des résultats biaisés.

 Reconnaissant la difficulté à obtenir des informations conformes et géographiquement diversifiées, Shaip propose des données de santé sous licence provenant d'une grande variété de régions spécifiquement organisées dans le but de construire des algorithmes précis. Ces données se présentent sous forme de texte, tels que des dossiers médicaux ou des informations sur les réclamations, des images de diagnostic médical telles que des tomodensitogrammes, des enregistrements audio tels que des notes orales de médecins ou des conversations entre médecins et patients, et même une vidéo des résultats de l'IRM. Il est également complètement anonymisé et anonymisé, protégeant votre organisation des implications éthiques et financières qui peuvent suivre une infraction à l'un des nombre croissant de réglementations qui régissent les données d'origine nationale et internationale.
Reconnaissant la difficulté à obtenir des informations conformes et géographiquement diversifiées, Shaip propose des données de santé sous licence provenant d'une grande variété de régions spécifiquement organisées dans le but de construire des algorithmes précis. Ces données se présentent sous forme de texte, tels que des dossiers médicaux ou des informations sur les réclamations, des images de diagnostic médical telles que des tomodensitogrammes, des enregistrements audio tels que des notes orales de médecins ou des conversations entre médecins et patients, et même une vidéo des résultats de l'IRM. Il est également complètement anonymisé et anonymisé, protégeant votre organisation des implications éthiques et financières qui peuvent suivre une infraction à l'un des nombre croissant de réglementations qui régissent les données d'origine nationale et internationale.
Surmonter les obstacles au développement de l'IA
Les efforts de développement de l'IA comportent des obstacles importants, quelle que soit l'industrie dans laquelle ils se déroulent, et le processus pour passer d'une idée réalisable à un produit réussi est semé d'embûches. Entre les défis d'acquérir les bonnes données et la nécessité de les anonymiser pour se conformer à toutes les réglementations pertinentes, il peut sembler que construire et former un algorithme est la partie facile.
Pour donner à votre organisation tous les avantages nécessaires dans l'effort de conception d'un nouveau développement d'IA révolutionnaire, vous voudrez envisager de vous associer à une entreprise comme Shaip. Chetan Parikh et Vatsal Ghiya ont fondé Shaip pour aider les entreprises à concevoir les types de solutions qui pourraient transformer les soins de santé aux États-Unis. clients à transformer des idées convaincantes en solutions d'IA.
Avec nos employés, nos processus et notre plate-forme travaillant pour votre organisation, vous pouvez immédiatement débloquer les quatre avantages suivants et catapulter votre projet vers une fin réussie :
1. La capacité de libérer vos data scientists
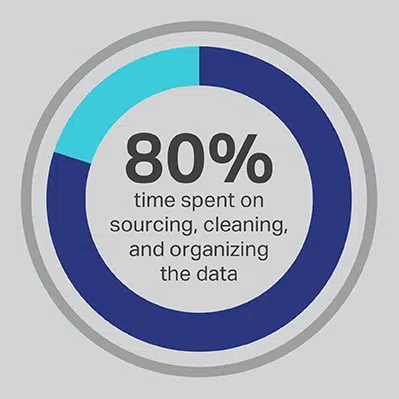
Il est indéniable que le processus de développement de l'IA prend un temps considérable, mais vous pouvez toujours optimiser les fonctions que votre équipe passe le plus de temps à exécuter. Vous avez embauché vos data scientists parce qu'ils sont experts dans le développement d'algorithmes avancés et de modèles d'apprentissage automatique, mais la recherche démontre systématiquement que ces travailleurs passent en réalité 80 % de leur temps à rechercher, nettoyer et organiser les données qui alimenteront le projet. Plus des trois quarts (76 %) des data scientists déclarent que ces processus de collecte de données banals sont également les parties les moins appréciées de leur travail, mais le besoin de données de qualité ne leur laisse que 20 % de leur temps pour le développement réel, ce qui est le travail le plus intéressant et le plus stimulant intellectuellement pour de nombreux scientifiques des données. En se procurant des données via un fournisseur tiers tel que Shaip, une entreprise peut laisser ses ingénieurs de données coûteux et talentueux externaliser leur travail en tant que concierges de données et passer leur temps sur les parties des solutions d'IA où ils peuvent produire le plus de valeur.
2. La capacité d'obtenir de meilleurs résultats
 De nombreux responsables du développement de l'IA décident d'utiliser des données open source ou crowdsourcing pour réduire les dépenses, mais cette décision finit presque toujours par coûter plus cher à long terme. Ces types de données sont facilement disponibles, mais ils ne peuvent pas égaler la qualité des ensembles de données soigneusement sélectionnés. Les données de crowdsourcing en particulier sont truffées d'erreurs, d'omissions et d'inexactitudes, et bien que ces problèmes puissent parfois être résolus au cours du processus de développement sous les yeux attentifs de vos ingénieurs, il faut des itérations supplémentaires qui ne seraient pas nécessaires si vous commenciez avec un niveau supérieur. -des données de qualité dès le départ.
De nombreux responsables du développement de l'IA décident d'utiliser des données open source ou crowdsourcing pour réduire les dépenses, mais cette décision finit presque toujours par coûter plus cher à long terme. Ces types de données sont facilement disponibles, mais ils ne peuvent pas égaler la qualité des ensembles de données soigneusement sélectionnés. Les données de crowdsourcing en particulier sont truffées d'erreurs, d'omissions et d'inexactitudes, et bien que ces problèmes puissent parfois être résolus au cours du processus de développement sous les yeux attentifs de vos ingénieurs, il faut des itérations supplémentaires qui ne seraient pas nécessaires si vous commenciez avec un niveau supérieur. -des données de qualité dès le départ.
S'appuyer sur des données open source est un autre raccourci courant qui comporte son propre ensemble d'écueils. Le manque de différenciation est l'un des plus gros problèmes, car un algorithme formé à l'aide de données open source est plus facilement répliqué qu'un algorithme basé sur des ensembles de données sous licence. En empruntant cette voie, vous invitez la concurrence d'autres entrants dans l'espace qui pourraient faire baisser vos prix et prendre des parts de marché à tout moment. Lorsque vous faites confiance à Shaip, vous accédez à des données de la plus haute qualité rassemblées par une main-d'œuvre habile et gérée, et nous pouvons vous accorder une licence exclusive pour un ensemble de données personnalisé qui empêche les concurrents de recréer facilement votre propriété intellectuelle durement gagnée.
3. Accès à des professionnels expérimentés
 Même si votre liste interne comprend des ingénieurs qualifiés et des data scientists talentueux, vos outils d'IA peuvent bénéficier de la sagesse qui ne vient que de l'expérience. Nos experts en la matière ont dirigé de nombreuses implémentations de l'IA dans leurs domaines et ont appris de précieuses leçons en cours de route, et leur seul objectif est de vous aider à atteindre le vôtre.
Même si votre liste interne comprend des ingénieurs qualifiés et des data scientists talentueux, vos outils d'IA peuvent bénéficier de la sagesse qui ne vient que de l'expérience. Nos experts en la matière ont dirigé de nombreuses implémentations de l'IA dans leurs domaines et ont appris de précieuses leçons en cours de route, et leur seul objectif est de vous aider à atteindre le vôtre.
Avec des experts du domaine identifiant, organisant, catégorisant et étiquetant les données pour vous, vous savez que les informations utilisées pour former votre algorithme peuvent produire les meilleurs résultats possibles. Nous menons également une assurance qualité régulière pour nous assurer que les données répondent aux normes les plus élevées et fonctionneront comme prévu non seulement dans un laboratoire, mais également dans une situation réelle.
4. Un calendrier de développement accéléré
Le développement de l'IA ne se fait pas du jour au lendemain, mais il peut arriver plus rapidement lorsque vous vous associez à Shaip. La collecte et l'annotation des données en interne créent un goulot d'étranglement opérationnel important qui retarde le reste du processus de développement. Travailler avec Shaip vous donne un accès instantané à notre vaste bibliothèque de données prêtes à l'emploi, et nos experts seront en mesure de trouver tout type d'entrées supplémentaires dont vous avez besoin grâce à notre connaissance approfondie de l'industrie et à notre réseau mondial. Sans le fardeau de la recherche et de l'annotation, votre équipe peut se mettre immédiatement au travail sur le développement réel, et notre modèle de formation peut aider à identifier les inexactitudes précoces afin de réduire les itérations nécessaires pour atteindre les objectifs de précision.
Si vous n'êtes pas prêt à externaliser tous les aspects de la gestion de vos données, Shaip propose également une plate-forme basée sur le cloud qui aide les équipes à produire, modifier et annoter plus efficacement différents types de données, y compris la prise en charge des images, de la vidéo, du texte et de l'audio. . ShaipCloud comprend une variété d'outils de validation et de workflow intuitifs, tels qu'une solution brevetée pour suivre et surveiller les charges de travail, un outil de transcription pour transcrire des enregistrements audio complexes et difficiles, et un composant de contrôle qualité pour garantir une qualité sans compromis. Mieux encore, il est évolutif, il peut donc évoluer à mesure que les diverses exigences de votre projet augmentent.
L'ère de l'innovation en IA ne fait que commencer, et nous verrons des progrès et des innovations incroyables dans les années à venir qui ont le potentiel de remodeler des industries entières ou même de modifier la société dans son ensemble. Chez Shaip, nous voulons utiliser notre expertise pour servir de force de transformation, aidant les entreprises les plus révolutionnaires au monde à exploiter la puissance des solutions d'IA pour atteindre des objectifs ambitieux.
Nous avons une expérience approfondie des applications de soins de santé et de l'IA conversationnelle, mais nous avons également les compétences nécessaires pour former des modèles pour presque tous les types d'applications. Pour plus d'informations sur la façon dont Shaip peut vous aider à faire passer votre projet de l'idée à la mise en œuvre, consultez les nombreuses ressources disponibles sur notre site Web ou contactez-nous dès aujourd'hui.
