
Les données sont la superpuissance qui transforme le paysage numérique dans le monde d'aujourd'hui. Des e-mails aux publications sur les réseaux sociaux, il y a des données partout. Il est vrai que les entreprises n'ont jamais eu accès à autant de données, mais est-ce suffisant d'avoir accès aux données ? La riche source d'information devient inutile ou obsolète lorsqu'elle n'est pas traitée.
Le texte non structuré peut être une riche source d'informations, mais il ne sera utile aux entreprises que si les données sont organisées, catégorisées et analysées. Les données non structurées, telles que le texte, l'audio, les vidéos et les médias sociaux, représentent 80-90% de toutes les données. De plus, à peine 18 % des organisations tireraient parti des données non structurées de leur organisation.
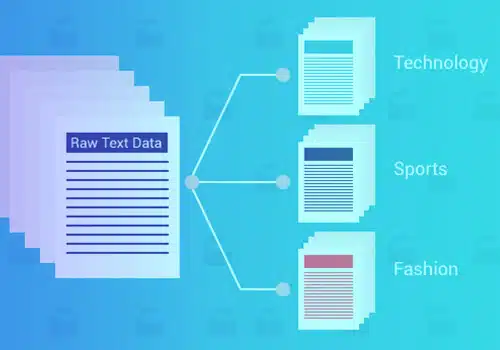
Passer au crible manuellement les téraoctets de données stockées sur les serveurs est une tâche chronophage et franchement impossible. Cependant, avec les progrès de l'apprentissage automatique, du traitement du langage naturel et de l'automatisation, il est possible de structurer et d'analyser les données textuelles rapidement et efficacement. La première étape de l'analyse des données est classification de texte.
Qu'est-ce que la classification de texte ?
La classification ou la catégorisation de texte est le processus de regroupement de texte en catégories ou classes prédéterminées. Grâce à cette approche d'apprentissage automatique, tout texte - documents, fichiers Web, études, documents juridiques, rapports médicaux, etc. – peuvent être classés, organisés et structurés.
La classification de texte est l'étape de base du traitement du langage naturel qui a plusieurs utilisations dans la détection du spam. Analyse des sentiments, détection d'intention, étiquetage des données, etc..
Cas d'utilisation possibles de la classification de texte
 L'utilisation de la classification de texte par apprentissage automatique présente plusieurs avantages, tels que l'évolutivité, la vitesse d'analyse, la cohérence et la capacité à prendre des décisions rapides sur la base de conversations en temps réel.
L'utilisation de la classification de texte par apprentissage automatique présente plusieurs avantages, tels que l'évolutivité, la vitesse d'analyse, la cohérence et la capacité à prendre des décisions rapides sur la base de conversations en temps réel.
Lorsque le modèle ML est formé sur l'IA qui classe automatiquement les éléments dans des catégories prédéfinies, vous pouvez rapidement convertir les navigateurs occasionnels en clients.
Processus de classification de texte
Le processus de classification de texte commence par le prétraitement, la sélection des fonctionnalités, l'extraction et la classification des données.

Pré-traitement
Tokenisation: Le texte est décomposé en formes de texte plus petites et plus simples pour une classification facile.
Normalisation: Tout le texte d'un document doit être au même niveau de compréhension. Certaines formes de normalisation comprennent,
- Maintenir les normes grammaticales ou structurelles dans le texte, telles que la suppression des espaces blancs ou des ponctuations. Ou en conservant des minuscules dans tout le texte.
- Supprimer les préfixes et les suffixes des mots et les ramener à leur mot racine.
- Suppression des mots vides tels que 'et' 'est' 'le' et plus qui n'ajoutent pas de valeur au texte.
Sélection de fonctionnalité
La sélection des caractéristiques est une étape fondamentale dans la classification de texte. Le processus vise à représenter les textes avec la caractéristique la plus pertinente. Les sélections de fonctionnalités permettent de supprimer les données non pertinentes et d'améliorer la précision.
La sélection des fonctionnalités réduit la variable d'entrée dans le modèle en utilisant uniquement les données les plus pertinentes et en éliminant le bruit. En fonction du type de solution que vous recherchez, vos modèles d'IA peuvent être conçus pour ne choisir que les fonctionnalités pertinentes du texte.
Extraction de caractéristiques
L'extraction de caractéristiques est une étape facultative que certaines entreprises entreprennent pour extraire des caractéristiques clés supplémentaires dans les données. L'extraction de caractéristiques utilise plusieurs techniques, telles que le mappage, le filtrage et le clustering. Le principal avantage de l'utilisation de l'extraction de caractéristiques est qu'elle permet de supprimer les données redondantes et d'améliorer la vitesse à laquelle le modèle ML est développé.
Balisage des données dans des catégories prédéterminées
Le balisage de texte dans des catégories prédéfinies est la dernière étape de la classification de texte. Cela peut se faire de trois manières différentes,
- Marquage manuel
- Correspondance basée sur des règles
- Algorithmes d'apprentissage - Les algorithmes d'apprentissage peuvent en outre être classés en deux catégories telles que le marquage supervisé et le marquage non supervisé.
- Apprentissage supervisé : le modèle ML peut aligner automatiquement les balises avec les données catégorisées existantes dans le balisage supervisé. Lorsque des données catégorisées sont déjà disponibles, les algorithmes ML peuvent mapper la fonction entre les balises et le texte.
- Apprentissage non supervisé : cela se produit lorsqu'il y a une pénurie de données étiquetées existantes. Les modèles ML utilisent des algorithmes de clustering et basés sur des règles pour regrouper des textes similaires, par exemple en fonction de l'historique des achats de produits, des avis, des détails personnels et des tickets. Ces grands groupes peuvent être analysés plus en détail pour tirer des informations précieuses spécifiques au client qui peuvent être utilisées pour concevoir des approches client personnalisées.
Il existe plusieurs cas d'utilisation pour la classification de texte dans les industries. Bien que la collecte, le regroupement, la classification et l'extraction d'informations précieuses à partir de données textuelles aient toujours été utilisées dans plusieurs domaines, la classification de texte trouve son potentiel dans le marketing, le développement de produits, le service client, la gestion et l'administration. Il aide les entreprises à acquérir une veille concurrentielle, une connaissance du marché et des clients et à prendre des décisions commerciales fondées sur des données.
Développer un outil de classification de texte efficace et perspicace n'est pas facile. Néanmoins, avec Shaip comme partenaire de données, vous pouvez développer un outil de classification de texte basé sur l'IA efficace, évolutif et rentable. Nous avons des tonnes de ensembles de données annotés avec précision et prêts à l'emploi qui peut être personnalisé pour les exigences uniques de votre modèle. Nous transformons votre texte en un avantage concurrentiel ; contactez-nous aujourd'hui.


