Internet a permis aux gens d'exprimer librement leurs opinions, points de vue et suggestions sur à peu près n'importe quoi dans le monde sur réseaux sociaux, sites Web et blogs. En plus d'exprimer leurs opinions, les gens (clients) influencent également les décisions d'achat des autres. Le sentiment, qu'il soit négatif ou positif, est essentiel pour toute entreprise ou marque soucieuse des ventes de ses produits ou services.
Aider les entreprises à extraire les commentaires à des fins professionnelles est Traitement du langage naturel. Une entreprise sur quatre a l'intention de mettre en œuvre la technologie NLP au cours de la prochaine année pour alimenter ses décisions commerciales. À l'aide de l'analyse des sentiments, la PNL aide les entreprises à tirer des informations interprétables à partir de données brutes et non structurées.
Exploration d'opinions ou l'analyse des sentiments est une technique de PNL utilisée pour identifier le sentiment exact – positif, négatif ou neutre – associés à des commentaires et à des retours d'expérience. Avec l'aide de la PNL, les mots-clés dans les commentaires sont analysés pour déterminer les mots positifs ou négatifs contenus dans le mot-clé.
Les sentiments sont notés sur un système d'échelle qui attribue des scores de sentiment aux émotions dans un morceau de texte (déterminant le texte comme positif ou négatif).
Qu'est-ce que l'analyse multilingue des sentiments ?

Comme son nom l'indique, analyse de sentiment multilingue est la technique consistant à effectuer des scores de sentiment pour plus d'une langue. Cependant, ce n'est pas aussi simple que cela. Notre culture, notre langue et nos expériences influencent grandement notre comportement d'achat et nos émotions. Sans une bonne compréhension de la langue, du contexte et de la culture de l'utilisateur, il est impossible de comprendre avec précision les intentions, les émotions et les interprétations de l'utilisateur.
Alors que l'automatisation est la réponse à bon nombre de nos problèmes modernes, traduction automatique le logiciel ne sera pas en mesure de saisir les nuances de la langue, les expressions familières, les subtilités et les références culturelles dans les commentaires et avis sur ce produit ça se traduit. L'outil ML peut vous donner une traduction, mais cela peut ne pas être utile. C'est la raison pour laquelle une analyse multilingue des sentiments est nécessaire.
Pourquoi l'analyse multilingue des sentiments est-elle nécessaire ?
La plupart des entreprises utilisent l'anglais comme moyen de communication, mais il n'est pas utilisé par la plupart des consommateurs dans le monde.
Selon Ethnologue, environ 13% de la population mondiale parle anglais. De plus, le British Council déclare qu'environ 25% de la population mondiale a une compréhension décente de l'anglais. Si l'on en croit ces chiffres, une grande partie des consommateurs interagissent entre eux et avec l'entreprise dans une langue autre que l'anglais.
Si l'objectif principal des entreprises est de conserver leur clientèle intacte et d'attirer de nouveaux clients, elles doivent comprendre intimement les opinions de leurs clients exprimées dans leurs langue maternelle. L'examen manuel de chaque commentaire ou sa traduction en anglais est un processus fastidieux qui ne donnera pas de résultats efficaces.
Une solution durable est de développer le multilingue systèmes d'analyse des sentiments qui détectent et analysent les opinions, les émotions et les suggestions des clients dans les médias sociaux, les forums, les enquêtes, etc.
Étapes pour effectuer une analyse de sentiment multilingue
L'analyse des sentiments, que ce soit dans une seule langue ou plusieurs langues, est un processus qui nécessite l'application de modèles d'apprentissage automatique, de traitement du langage naturel et de techniques d'analyse de données pour extraire score de sentiment multilingue à partir des données.
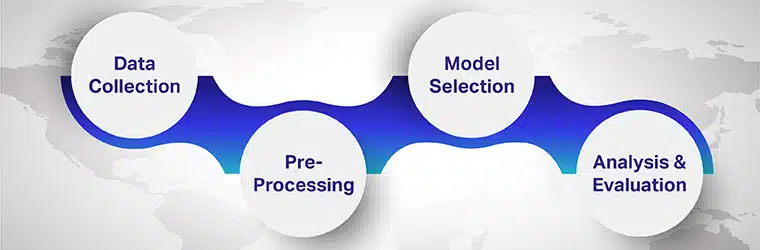
Les étapes impliquées dans l'analyse des sentiments multilingues sont
Étape 1 : Collecte de données
La collecte de données est la première étape de l'application de l'analyse des sentiments. Pour créer un multilingue modèle d'analyse des sentiments, il est important d'acquérir des données dans une variété de langues. Tout dépendra de la qualité des données recueillies, annotées et étiquetées. Vous pouvez extraire des données d'API, de référentiels open source et d'éditeurs.
Étape 2 : Pré-traitement
Les données Web collectées doivent être nettoyées et les informations recueillies à partir de celles-ci. Les parties du texte qui n'ont aucune signification particulière, telles que « le » « est » et plus encore, doivent être supprimées. De plus, le texte doit être regroupé en groupes de mots à catégoriser pour transmettre une signification positive ou négative.
Pour améliorer la qualité de la classification, le contenu doit être nettoyé du bruit, tel que les balises HTML, les publicités et les scripts. La langue, le lexique et la grammaire utilisés par les gens sont différents selon le réseau social. Il est important de normaliser ce contenu et de le préparer pour le prétraitement.
Une autre étape critique du prétraitement consiste à utiliser le traitement du langage naturel pour diviser les phrases, supprimer les mots vides, baliser les parties du discours, transformer les mots en leur forme racine et symboliser les mots en symboles et en texte.
Étape 3 : Sélection du modèle
Modèle basé sur des règles : La méthode la plus simple d'analyse sémantique multilingue est basée sur des règles. L'algorithme basé sur des règles effectue l'analyse sur la base d'un ensemble de règles prédéterminées programmées par les experts.
La règle peut spécifier des mots ou des phrases qui sont positifs ou négatifs. Si vous prenez un avis sur un produit ou un service, par exemple, il peut contenir des mots positifs ou négatifs tels que "génial", "lent", "attendez" et "utile". Cette méthode facilite la classification des mots, mais elle peut mal classer les mots compliqués ou moins fréquents.
Modèle automatique : Le modèle automatique effectue une analyse multilingue des sentiments sans l'intervention de modérateurs humains. Bien que le modèle d'apprentissage automatique soit construit à l'aide d'un effort humain, il peut fonctionner automatiquement pour fournir des résultats précis une fois développé.
Les données de test sont analysées et chaque commentaire est étiqueté manuellement comme positif ou négatif. Le modèle ML apprendra ensuite des données de test en comparant le nouveau texte avec les commentaires existants et en les catégorisant.
Étape 4 : Analyse et évaluation
Les modèles basés sur des règles et d'apprentissage automatique peuvent être améliorés et améliorés au fil du temps et de l'expérience. Un lexique de mots moins fréquemment utilisés ou des scores en direct pour les sentiments multilingues peuvent être mis à jour pour une classification plus rapide et plus précise.
Le défi de la traduction
La traduction ne suffit-elle pas ? En fait non!
La traduction consiste à transférer un texte ou des groupes de texte d'une langue et à trouver un équivalent dans une autre. Cependant, la traduction n'est ni simple ni efficace.
C'est parce que les humains utilisent le langage non seulement pour communiquer leurs besoins mais aussi pour exprimer leurs émotions. De plus, il existe de grandes différences entre les différentes langues, telles que l'anglais, l'hindi, le mandarin et le thaï. Ajoutez à ce mélange littéraire l'utilisation d'émotions, d'argot, d'idiomes, de sarcasme et d'emojis. Il n'est pas possible d'obtenir une traduction exacte du texte.
Certains des principaux défis de traduction automatique
- Subjectivité
- Comportementale
- Argot et idiomes
- Sarcasme
- Comparaisons
- Neutralité
- Emojis et usage moderne des mots.
Sans une compréhension précise de la signification des avis, commentaires et communications concernant leurs produits, prix, services, caractéristiques et qualité, les entreprises seront incapables de comprendre les besoins et les opinions des clients.
L'analyse des sentiments multilingues est un processus difficile. Chaque langue a son propre lexique, sa syntaxe, sa morphologie et sa phonologie. Ajoutez à cela la culture, l'argot, sentiments exprimés, sarcasme et tonalité, et vous avez un casse-tête difficile qui nécessite une solution de ML efficace alimentée par l'IA.
Un ensemble de données multilingue complet est nécessaire pour développer des outils d'analyse des sentiments qui peut traiter les avis et fournir des informations puissantes aux entreprises. Shaip est le leader du marché dans la fourniture d'ensembles de données personnalisés, étiquetés et annotés dans plusieurs langues qui aident à développer des données efficaces et précises. solutions multilingues d'analyse des sentiments.