
L'IA, le Big Data et l'apprentissage automatique continuent d'influencer les décideurs politiques, les entreprises, la science, les médias et une variété d'industries à travers le monde. Les rapports suggèrent que le taux d'adoption mondial de l'IA est actuellement à 35% en 2022 – une énorme augmentation de 4 % par rapport à 2021. 42 % supplémentaires d'entreprises exploreraient les nombreux avantages de l'IA pour leur entreprise.
Alimenter les nombreuses initiatives d'IA et Machine Learning les solutions sont des données. L'IA ne peut être aussi bonne que les données qui alimentent l'algorithme. Des données de mauvaise qualité pourraient entraîner des résultats de mauvaise qualité et des prévisions inexactes.
Bien qu'il y ait eu beaucoup d'attention sur le développement de solutions ML et AI, la prise de conscience de ce qui se qualifie comme un ensemble de données de qualité fait défaut. Dans cet article, nous parcourons la chronologie de données de formation en IA de qualité et identifier l'avenir de l'IA grâce à une compréhension de la collecte de données et de la formation.
Définition des données d'entraînement IA
Lors de la création d'une solution ML, la quantité et la qualité de l'ensemble de données de formation sont importantes. Le système ML nécessite non seulement de gros volumes de données de formation dynamiques, impartiales et précieuses, mais il en a également besoin de beaucoup.
Mais qu'est-ce que les données d'entraînement de l'IA ?
Les données d'entraînement de l'IA sont une collection de données étiquetées utilisées pour entraîner l'algorithme ML afin de faire des prédictions précises. Le système ML essaie de reconnaître et d'identifier des modèles, de comprendre les relations entre les paramètres, de prendre les décisions nécessaires et d'évaluer en fonction des données de formation.
Prenons l'exemple des voitures autonomes, par exemple. L'ensemble de données de formation pour un modèle de ML autonome doit inclure des images et des vidéos étiquetées de voitures, de piétons, de panneaux de signalisation et d'autres véhicules.
En bref, pour améliorer la qualité de l'algorithme ML, vous avez besoin de grandes quantités de données d'apprentissage bien structurées, annotées et étiquetées.
Importance des données de formation de qualité et son évolution
Des données de formation de haute qualité sont la clé du développement d'applications d'IA et de ML. Les données sont collectées à partir de diverses sources et présentées sous une forme non organisée inadaptée à des fins d'apprentissage automatique. Les données de formation de qualité - étiquetées, annotées et étiquetées - sont toujours dans un format organisé - idéal pour la formation ML.
Des données de formation de qualité permettent au système ML de reconnaître plus facilement les objets et de les classer selon des caractéristiques prédéterminées. L'ensemble de données pourrait produire de mauvais résultats de modèle si la classification n'est pas précise.
Les premiers jours des données d'entraînement à l'IA
Bien que l'IA domine le monde actuel des affaires et de la recherche, les premiers jours avant la domination du ML Intelligence artificielle était bien différent.
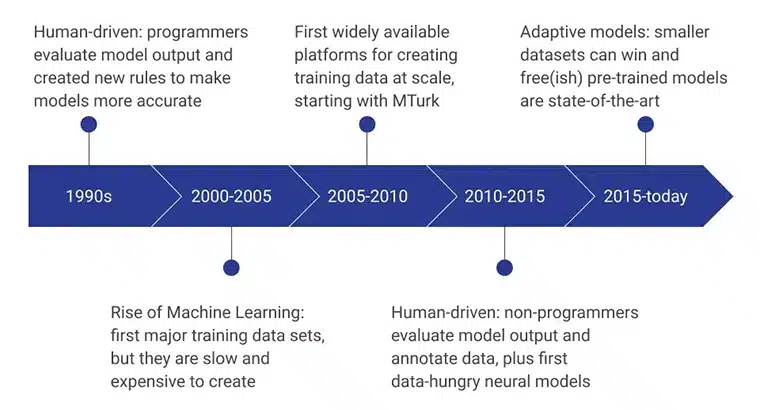
Les premières étapes des données d'entraînement de l'IA ont été alimentées par des programmeurs humains qui ont évalué la sortie du modèle en concevant systématiquement de nouvelles règles qui ont rendu le modèle plus efficace. Au cours de la période 2000-2005, le premier ensemble de données majeur a été créé, et il s'agissait d'un processus extrêmement lent, dépendant des ressources et coûteux. Cela a conduit au développement d'ensembles de données de formation à grande échelle, et MTurk d'Amazon a joué un rôle important dans l'évolution des perceptions des gens à l'égard de la collecte de données. Simultanément, l'étiquetage et l'annotation humains ont également décollé.
Les années suivantes se sont concentrées sur la création et l'évaluation des modèles de données par des non-programmeurs. Actuellement, l'accent est mis sur les modèles pré-formés développés à l'aide de méthodes avancées de collecte de données de formation.
La quantité plutôt que la qualité
Lors de l'évaluation de l'intégrité des ensembles de données de formation à l'IA à l'époque, les scientifiques des données se sont concentrés sur Quantité de données d'entraînement à l'IA sur la qualité.
Par exemple, il y avait une idée fausse commune selon laquelle les grandes bases de données fournissent des résultats précis. Le simple volume de données était considéré comme un bon indicateur de la valeur des données. La quantité n'est que l'un des principaux facteurs déterminant la valeur de l'ensemble de données – le rôle de la qualité des données a été reconnu.
La prise de conscience que qualité des données dépendaient de l'exhaustivité, de la fiabilité, de la validité, de la disponibilité et de l'actualité des données. Plus important encore, la pertinence des données pour le projet a déterminé la qualité des données recueillies.
Limites des premiers systèmes d'IA en raison de données de formation médiocres
La médiocrité des données de formation, associée au manque de systèmes informatiques avancés, a été l'une des raisons de plusieurs promesses non tenues des premiers systèmes d'IA.
En raison du manque de données de formation de qualité, les solutions ML n'ont pas pu identifier avec précision les modèles visuels qui bloquent le développement de la recherche neuronale. Bien que de nombreux chercheurs aient identifié la promesse de la reconnaissance de la langue parlée, la recherche ou le développement d'outils de reconnaissance de la parole n'a pas pu se concrétiser en raison du manque d'ensembles de données sur la parole. Un autre obstacle majeur au développement d'outils d'IA haut de gamme était le manque de capacités de calcul et de stockage des ordinateurs.
Le passage à des données de formation de qualité
Il y a eu un changement marqué dans la prise de conscience que la qualité de l'ensemble de données est importante. Pour que le système ML imite avec précision l'intelligence humaine et les capacités de prise de décision, il doit s'appuyer sur des données de formation volumineuses et de haute qualité.
Considérez vos données de ML comme une enquête : plus le échantillon de données taille, meilleure est la prédiction. Si l'échantillon de données n'inclut pas toutes les variables, il se peut qu'il ne reconnaisse pas les modèles ou n'apporte pas de conclusions inexactes.
Les progrès de la technologie de l'IA et le besoin de meilleures données de formation
 Les progrès de la technologie de l'IA augmentent le besoin de données de formation de qualité.
Les progrès de la technologie de l'IA augmentent le besoin de données de formation de qualité.La compréhension que de meilleures données de formation augmentent les chances de modèles ML fiables a donné lieu à de meilleures méthodologies de collecte de données, d'annotation et d'étiquetage. La qualité et la pertinence des données ont eu un impact direct sur la qualité du modèle d'IA.
 Les progrès de la technologie de l'IA augmentent le besoin de données de formation de qualité.
Les progrès de la technologie de l'IA augmentent le besoin de données de formation de qualité.Accent accru sur la qualité et l'exactitude des données
Pour que le modèle ML commence à fournir des résultats précis, il est alimenté par des ensembles de données de qualité qui passent par des étapes itératives d'affinement des données.
Par exemple, un être humain pourrait être capable de reconnaître une race de chien spécifique quelques jours après avoir été initié à la race - à travers des photos, des vidéos ou en personne. Les humains tirent parti de leur expérience et des informations connexes pour se souvenir et extraire ces connaissances si nécessaire. Pourtant, cela ne fonctionne pas aussi facilement pour une machine. La machine doit être alimentée avec des images clairement annotées et étiquetées - des centaines ou des milliers - de cette race particulière et d'autres races pour qu'elle puisse établir la connexion.
Un modèle d'IA prédit le résultat en corrélant les informations formées avec les informations présentées dans le monde réel. L'algorithme est rendu inutile si les données d'apprentissage ne contiennent pas d'informations pertinentes.
Importance de données de formation diverses et représentatives
Une diversité accrue des données augmente également la compétence, réduit les biais et renforce la représentation équitable de tous les scénarios. Si le modèle d'IA est formé à l'aide d'un ensemble de données homogène, vous pouvez être sûr que la nouvelle application ne fonctionnera que dans un but précis et servira une population spécifique.Un ensemble de données pourrait être biaisé en faveur d'une population, d'une race, d'un sexe, d'un choix et d'opinions intellectuelles particuliers, ce qui pourrait conduire à un modèle inexact.
Il est important de s'assurer que l'ensemble du processus de collecte de données, y compris la sélection du pool de sujets, la conservation, l'annotation et l'étiquetage, est suffisamment diversifié, équilibré et représentatif de la population.
 Une diversité accrue des données augmente également la compétence, réduit les biais et renforce la représentation équitable de tous les scénarios. Si le modèle d'IA est formé à l'aide d'un ensemble de données homogène, vous pouvez être sûr que la nouvelle application ne fonctionnera que dans un but précis et servira une population spécifique.
Une diversité accrue des données augmente également la compétence, réduit les biais et renforce la représentation équitable de tous les scénarios. Si le modèle d'IA est formé à l'aide d'un ensemble de données homogène, vous pouvez être sûr que la nouvelle application ne fonctionnera que dans un but précis et servira une population spécifique.L'avenir des données d'entraînement à l'IA
Le succès futur des modèles d'IA dépend de la qualité et de la quantité des données de formation utilisées pour former les algorithmes ML. Il est essentiel de reconnaître que cette relation entre la qualité et la quantité des données est spécifique à la tâche et n'a pas de réponse définitive.
En fin de compte, l'adéquation d'un ensemble de données de formation est définie par sa capacité à fonctionner de manière fiable pour l'objectif pour lequel il a été créé.
Avancées dans la collecte de données et les techniques d'annotation
Étant donné que le ML est sensible aux données alimentées, il est essentiel de rationaliser les politiques de collecte et d'annotation des données. Les erreurs dans la collecte des données, la conservation, les fausses déclarations, les mesures incomplètes, le contenu inexact, la duplication des données et les mesures erronées contribuent à une qualité insuffisante des données.
La collecte automatisée de données via l'exploration de données, le grattage Web et l'extraction de données ouvre la voie à une génération de données plus rapide. De plus, les ensembles de données pré-emballés agissent comme une technique de collecte de données rapide.
Le crowdsourcing est une autre méthode révolutionnaire de collecte de données. Bien que la véracité des données ne puisse être garantie, il s'agit d'un excellent outil pour recueillir l'image publique. Enfin spécialisé collecte de données les experts fournissent également des données provenant d'objectifs spécifiques.
Accent accru sur les considérations éthiques dans les données de formation
Avec les progrès rapides de l'IA, plusieurs problèmes éthiques sont apparus, en particulier dans la collecte de données de formation. Certaines considérations éthiques dans la collecte de données de formation incluent le consentement éclairé, la transparence, les préjugés et la confidentialité des données.Étant donné que les données incluent désormais tout, des images faciales, des empreintes digitales, des enregistrements vocaux et d'autres données biométriques critiques, il devient extrêmement important de garantir le respect des pratiques légales et éthiques pour éviter des poursuites coûteuses et des atteintes à la réputation.
Le potentiel de données d'entraînement encore plus qualitatives et diversifiées à l'avenir
Il y a un énorme potentiel pour des données d'entraînement de haute qualité et diversifiées à l'avenir. Grâce à la sensibilisation à la qualité des données et à la disponibilité de fournisseurs de données qui répondent aux exigences de qualité des solutions d'IA.
Les fournisseurs de données actuels sont aptes à utiliser des technologies révolutionnaires pour obtenir de manière éthique et légale des quantités massives d'ensembles de données divers. Ils disposent également d'équipes internes pour étiqueter, annoter et présenter les données personnalisées pour différents projets ML.
 Avec les progrès rapides de l'IA, plusieurs problèmes éthiques sont apparus, en particulier dans la collecte de données de formation. Certaines considérations éthiques dans la collecte de données de formation incluent le consentement éclairé, la transparence, les préjugés et la confidentialité des données.
Avec les progrès rapides de l'IA, plusieurs problèmes éthiques sont apparus, en particulier dans la collecte de données de formation. Certaines considérations éthiques dans la collecte de données de formation incluent le consentement éclairé, la transparence, les préjugés et la confidentialité des données.Conclusion
Il est important de s'associer à des fournisseurs fiables ayant une compréhension aiguë des données et de la qualité pour développer des modèles d'IA haut de gamme. Shaip est la première société d'annotation apte à fournir des solutions de données personnalisées qui répondent aux besoins et aux objectifs de votre projet d'IA. Faites équipe avec nous et explorez les compétences, l'engagement et la collaboration que nous apportons à la table.


