
L'intelligence artificielle et le Big Data ont le potentiel de trouver des solutions aux problèmes mondiaux tout en donnant la priorité aux problèmes locaux et en transformant le monde de nombreuses manières profondes. L'IA apporte des solutions à tous - et dans tous les contextes, des foyers aux lieux de travail. Ordinateurs IA, avec Machine Learning formation, peut simuler un comportement intelligent et des conversations de manière automatisée mais personnalisée.
Pourtant, l'IA est confrontée à un problème d'inclusion et est souvent biaisée. Heureusement, en se concentrant sur éthique de l'intelligence artificielle peut inaugurer de nouvelles possibilités en termes de diversification et d'inclusion en éliminant les préjugés inconscients grâce à diverses données de formation.
Importance de la diversité dans les données de formation en IA
 La diversité et la qualité des données de formation sont liées puisque l'une affecte l'autre et a un impact sur le résultat de la solution d'IA. Le succès de la solution d'IA dépend de la données diverses il est entraîné. La diversité des données empêche l'IA de se suradapter, ce qui signifie que le modèle n'exécute ou n'apprend qu'à partir des données utilisées pour l'entraînement. Avec le surajustement, le modèle d'IA ne peut pas fournir de résultats lorsqu'il est testé sur des données non utilisées dans la formation.
La diversité et la qualité des données de formation sont liées puisque l'une affecte l'autre et a un impact sur le résultat de la solution d'IA. Le succès de la solution d'IA dépend de la données diverses il est entraîné. La diversité des données empêche l'IA de se suradapter, ce qui signifie que le modèle n'exécute ou n'apprend qu'à partir des données utilisées pour l'entraînement. Avec le surajustement, le modèle d'IA ne peut pas fournir de résultats lorsqu'il est testé sur des données non utilisées dans la formation.
L'état actuel de la formation en IA données
L'inégalité ou le manque de diversité des données conduirait à des solutions d'IA injustes, contraires à l'éthique et non inclusives qui pourraient aggraver la discrimination. Mais comment et pourquoi la diversité des données est-elle liée aux solutions d'IA ?
Une représentation inégale de toutes les classes conduit à une identification erronée des visages - un exemple important est Google Photos qui a classé un couple noir comme "gorilles". Et Meta invite un utilisateur regardant une vidéo d'hommes noirs s'il souhaite "continuer à regarder des vidéos de primates".
Par exemple, une classification inexacte ou inappropriée des minorités ethniques ou raciales, en particulier dans les chatbots, pourrait entraîner des préjugés dans les systèmes de formation à l'IA. Selon le rapport 2019 sur Systèmes discriminants - Genre, race, pouvoir dans l'IA, plus de 80% des professeurs d'IA sont des hommes ; les femmes chercheuses en IA sur FB ne représentent que 15% et 10% sur Google.
L'impact de diverses données d'entraînement sur les performances de l'IA
 Laisser de côté des groupes et des communautés spécifiques de la représentation des données peut entraîner des algorithmes biaisés.
Laisser de côté des groupes et des communautés spécifiques de la représentation des données peut entraîner des algorithmes biaisés.
Le biais des données est souvent introduit accidentellement dans les systèmes de données - en sous-échantillonnant certaines races ou certains groupes. Lorsque les systèmes de reconnaissance faciale sont formés sur divers visages, cela aide le modèle à identifier des caractéristiques spécifiques, telles que la position des organes faciaux et les variations de couleur.
Un autre résultat d'avoir une fréquence déséquilibrée d'étiquettes est que le système peut considérer une minorité comme une anomalie lorsqu'il est pressurisé pour produire une sortie dans un court laps de temps.
Atteindre la diversité dans les données de formation en IA
D'un autre côté, générer un ensemble de données diversifié est également un défi. Le simple manque de données sur certaines classes pourrait entraîner une sous-représentation. Il peut être atténué en rendant les équipes de développeurs d'IA plus diversifiées en termes de compétences, d'ethnicité, de race, de sexe, de discipline, etc. De plus, la façon idéale de résoudre les problèmes de diversité des données dans l'IA est de les affronter dès le départ au lieu d'essayer de réparer ce qui est fait - en insufflant de la diversité au stade de la collecte et de la conservation des données.
Indépendamment du battage médiatique autour de l'IA, cela dépend toujours des données collectées, sélectionnées et entraînées par les humains. Le biais inné chez les humains se reflétera dans les données collectées par eux, et ce biais inconscient se glisse également dans les modèles ML.
Étapes de collecte et de conservation de diverses données de formation
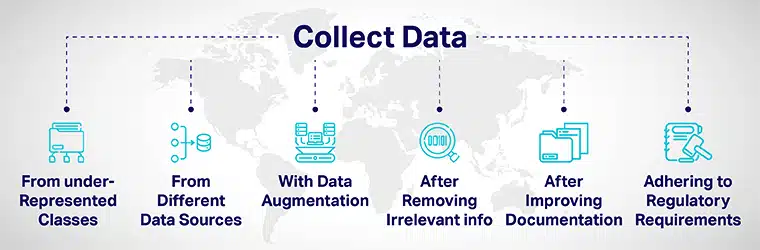
Diversité des données peut être atteint par :
- Ajoutez judicieusement plus de données provenant de classes sous-représentées et exposez vos modèles à divers points de données.
- En rassemblant des données à partir de différentes sources de données.
- En augmentant les données ou en manipulant artificiellement des ensembles de données pour augmenter/inclure de nouveaux points de données distinctement différents des points de données d'origine.
- Lors de l'embauche de candidats pour le processus de développement de l'IA, supprimez toutes les informations non pertinentes pour l'emploi de la candidature.
- Améliorer la transparence et la responsabilité en améliorant la documentation du développement et de l'évaluation des modèles.
- Mettre en place des réglementations pour favoriser la diversité et inclusivité dans l'IA systèmes à partir de la base. Divers gouvernements ont élaboré des lignes directrices pour garantir la diversité et atténuer les biais de l'IA qui peuvent produire des résultats injustes.
[ Lire aussi : En savoir plus sur le processus de collecte de données de formation à l'IA ]
Conclusion
Actuellement, seules quelques grandes entreprises technologiques et centres d'apprentissage sont exclusivement impliqués dans le développement de solutions d'IA. Ces espaces élitistes sont imprégnés d'exclusion, de discrimination et de préjugés. Cependant, ce sont les espaces où l'IA est en cours de développement, et la logique derrière ces systèmes d'IA avancés est remplie des mêmes préjugés, discriminations et exclusions que subissent les groupes sous-représentés.
Tout en discutant de la diversité et de la non-discrimination, il est important de s'interroger sur les personnes dont elle profite et celles dont elle nuit. Nous devrions également regarder qui cela désavantage – en forçant l'idée d'une personne « normale », l'IA pourrait potentiellement mettre « les autres » en danger.
Discuter de la diversité des données d'IA sans reconnaître les relations de pouvoir, l'équité et la justice ne montrera pas la situation dans son ensemble. Pour bien comprendre l'étendue de la diversité des données de formation en IA et comment les humains et l'IA peuvent ensemble atténuer cette crise, contacter les ingénieurs de Shaip. Nous avons divers ingénieurs en IA qui peuvent fournir des données dynamiques et diverses pour vos solutions d'IA.


