
La reconnaissance automatique de la parole (ASR) a parcouru un long chemin. Bien qu'il ait été inventé il y a longtemps, il n'a presque jamais été utilisé par personne. Cependant, le temps et la technologie ont maintenant considérablement changé. La transcription audio a considérablement évolué.
Des technologies telles que l'IA (intelligence artificielle) ont alimenté le processus de traduction audio-texte pour des résultats rapides et précis. En conséquence, ses applications dans le monde réel ont également augmenté, certaines applications populaires telles que Tik Tok, Spotify et Zoom intégrant le processus dans leurs applications mobiles.
Alors explorons l'ASR et découvrons pourquoi c'est l'une des technologies les plus populaires en 2022.
Qu'est-ce que la parole en texte ?
La parole en texte est une technologie améliorée par l'IA qui traduit la parole humaine d'une forme analogique à une forme numérique. De plus, la forme numérique des données collectées est transcrite dans un format texte.
La synthèse vocale est souvent confondue avec la reconnaissance vocale, qui est entièrement différente de cette méthode. Dans la reconnaissance vocale, l'accent est mis sur l'identification des modèles de voix des personnes, alors que, dans cette méthode, le système essaie d'identifier les mots prononcés.
Noms communs de la parole au texte
Cette technologie avancée de reconnaissance vocale est également populaire et désignée par les noms :
- Reconnaissance vocale automatique (ASR)
- Reconnaissance de la parole
- Reconnaissance vocale par ordinateur
- Transcription audio
- Lecture d'écran
Comprendre le fonctionnement de la reconnaissance automatique de la parole
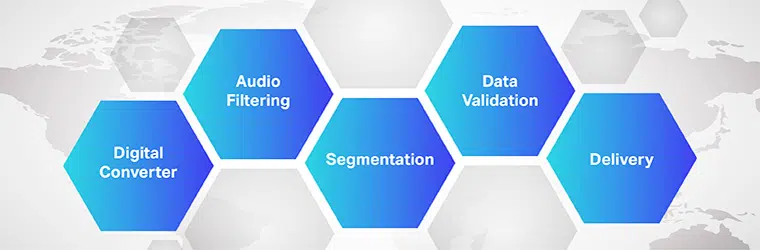
Le fonctionnement d'un logiciel de traduction audio-texte est complexe et implique la mise en œuvre de plusieurs étapes. Comme nous le savons, speech-to-text est un logiciel exclusif conçu pour convertir des fichiers audio en un format texte modifiable ; il le fait en tirant parti de la reconnaissance vocale.
Processus
- Initialement, à l'aide d'un convertisseur analogique-numérique, un programme informatique applique des algorithmes linguistiques aux données fournies pour distinguer les vibrations des signaux auditifs.
- Ensuite, les sons pertinents sont filtrés en mesurant les ondes sonores.
- De plus, les sons sont distribués/segmentés en centièmes ou millièmes de secondes et mis en correspondance avec des phonèmes (une unité de son mesurable pour différencier un mot d'un autre).
- Les phonèmes sont ensuite exécutés à travers un modèle mathématique pour comparer les données existantes avec des mots, des phrases et des phrases bien connus.
- La sortie est un texte ou un fichier audio informatique.
[A également lu: Un aperçu complet de la reconnaissance vocale automatique]

Quelles sont les utilisations de la parole au texte ?
Il existe de multiples utilisations de logiciels de reconnaissance vocale automatique, telles que
- Recherche de contenu : La plupart d'entre nous sont passés de taper des lettres sur nos téléphones à appuyer sur un bouton pour que le logiciel reconnaisse notre voix et fournisse les résultats souhaités.
- Service Client : Les chatbots et les assistants IA qui peuvent guider les clients à travers les quelques premières étapes du processus sont devenus courants.
- Sous-titrage en temps réel: Avec un accès mondial accru au contenu, le sous-titrage en temps réel est devenu un marché important et important, poussant l'ASR vers l'avant pour son utilisation.
- Documents électroniques : Plusieurs services administratifs ont commencé à utiliser ASR à des fins de documentation, pour une meilleure rapidité et efficacité.
Quels sont les principaux défis de la reconnaissance vocale ?
Annotation audio n'a pas encore atteint le sommet de son développement. Les ingénieurs tentent encore de relever de nombreux défis pour rendre le système efficace, tels que
- Maîtriser les accents et les dialectes.
- Comprendre le contexte des phrases prononcées.
- Séparation des bruits de fond pour amplifier la qualité d'entrée.
- Commutation du code dans différentes langues pour un traitement efficace.
- Analyser les repères visuels utilisés dans le discours dans le cas de fichiers vidéo.
Transcriptions audio et développement de l'IA Speech-to-Text
Le plus grand défi avec le logiciel de reconnaissance automatique de la parole est de créer sa sortie avec 100% de précision. Comme les données brutes sont dynamiques et qu'un seul algorithme ne peut pas être appliqué, les données sont annotées pour entraîner l'IA à les comprendre dans le bon contexte.
Pour effectuer ce processus, des tâches spécifiques sont à mettre en œuvre, telles que :
 Reconnaissance d'entité nommée (NER) : TNS est le processus d'identification et de segmentation de différentes entités nommées en catégories spécifiques.
Reconnaissance d'entité nommée (NER) : TNS est le processus d'identification et de segmentation de différentes entités nommées en catégories spécifiques.- Analyse des sentiments et des sujets : Le logiciel utilisant plusieurs algorithmes effectue l'analyse des sentiments des données fournies pour fournir des résultats sans erreur.
 Reconnaissance d'entité nommée (NER) :
Reconnaissance d'entité nommée (NER) : - Analyse d'intention et de conversation : La détection d'intention vise à entraîner l'IA à reconnaître l'intention du locuteur. Il est principalement utilisé pour créer des chatbots alimentés par l'IA.
Conclusion
La technologie de la parole en texte est à un stade formidable en ce moment. Avec de plus en plus d'appareils numériques intégrant des assistants de recherche et de contrôle vocaux dans leurs applications, la demande de transcription audio devrait augmenter. Si vous souhaitez ajouter cette fonctionnalité impressionnante à votre application, contactez les experts en collecte de données vocales de Shaip pour connaître tous les détails.


