
Les systèmes de reconnaissance automatique de la parole et les assistants virtuels tels que Siri, Alexa et Cortana font désormais partie intégrante de nos vies. Notre dépendance à leur égard augmente considérablement à mesure qu'ils deviennent plus intelligents. Qu'il s'agisse d'allumer nos lumières, de passer des appels ou de changer de chaîne de télévision, nous tirons parti de ces technologies intelligentes pour accomplir des tâches banales.
Cependant, vous êtes-vous déjà demandé comment fonctionnent ces systèmes de reconnaissance vocale ?
Eh bien, ce blog vous renseignera sur certains des principes fondamentaux de la reconnaissance automatique de la parole. Nous explorerons également son fonctionnement et la manière dont les assistants virtuels fonctionnels tels que Siri sont construits.
Qu'est-ce que la reconnaissance vocale automatique ?
La reconnaissance automatique de la parole (ASR) est un logiciel qui permet au système informatique de convertir la parole humaine en texte, en exploitant plusieurs algorithmes d'intelligence artificielle et d'apprentissage automatique.
Après avoir converti et analysé la commande donnée, l'ordinateur répond avec une sortie appropriée pour l'utilisateur. ASR a été introduit pour la première fois en 1962, et depuis lors, il n'a cessé d'améliorer ses opérations et d'être mis en lumière grâce à des applications populaires comme Alexa et Siri.
Quel est le processus de collecte de parole pour la formation de modèles ASR ?
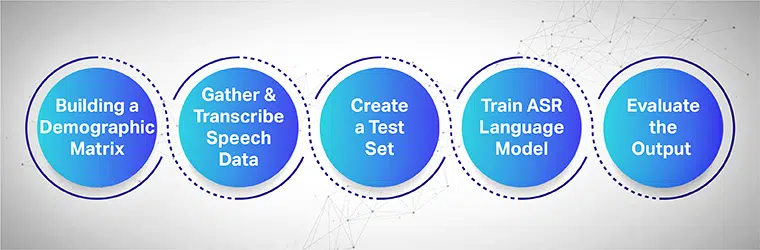
La collecte de discours vise à rassembler plusieurs échantillons d'enregistrements provenant de plusieurs zones utilisées pour alimenter et former des modèles ASR. Le système ASR offre la plus grande efficacité lorsque de grands ensembles de données vocales et audio sont collectés et fournis à son système.
Pour fonctionner de manière transparente, les ensembles de données vocales collectées doivent contenir toutes les données démographiques, langues, accents et dialectes cibles. Le processus suivant montre comment entraîner le modèle d'apprentissage automatique en plusieurs étapes :
Commencez par construire une matrice démographique
Collecte avant tout les données pour différentes données démographiques telles que l'emplacement, le sexe, la langue, l'âge et les accents. Assurez-vous également de capturer une variété de bruits environnementaux tels que le bruit de la rue, le bruit de la salle d'attente, le bruit des bureaux publics, etc.
Recueillir et transcrire les données vocales
L'étape suivante consiste à collecter des échantillons audio et vocaux humains basés sur différents emplacements géographiques pour former votre modèle ASR. Il s'agit d'une étape importante qui nécessite que des experts humains prononcent des mots longs et courts pour obtenir la sensation authentique de la phrase et répètent les mêmes phrases dans différents accents et dialectes.
Créer une campagne de test distincte
Une fois que vous avez rassemblé le texte transcrit, l'étape suivante consiste à le coupler avec les données audio correspondantes. Ensuite, segmentez davantage les données et incluez-en une déclaration. Désormais, à partir des paires de données segmentées, vous pouvez extraire des données aléatoires d'un ensemble pour des tests supplémentaires.
Entraînez votre modèle de langage ASR
Plus vos ensembles de données contiennent d'informations, meilleures seront les performances de votre modèle formé par l'IA. Par conséquent, générez plusieurs variations de texte et de discours que vous avez enregistrés précédemment. Paraphrasez les mêmes phrases en utilisant différentes notations vocales.
Évaluer la sortie et enfin, itérer
Enfin, mesurez la sortie de votre modèle ASR pour fixer ses performances. Testez le modèle par rapport à un ensemble de tests pour déterminer son efficacité. De manière appropriée, engagez votre modèle ASR dans une boucle de rétroaction pour générer la sortie souhaitée et corriger les lacunes.
[A également lu: Un aperçu complet de la reconnaissance vocale automatique]

Quels sont les différents cas d'utilisation de la reconnaissance vocale ?
La technologie de reconnaissance vocale est très répandue dans de nombreuses industries aujourd'hui. Certaines industries utilisant cette formidable technologie sont les suivantes :
 Industrie alimentaire: Des géants de l'alimentation tels que Wendy's et McDonald's sont prêts à améliorer l'expérience de leurs clients grâce à l'ASR. Dans bon nombre de leurs points de vente, ils ont déployé des modèles ASR entièrement fonctionnels pour prendre les commandes et les transmettre ensuite à la section de cuisine pour préparer la commande du client.
Industrie alimentaire: Des géants de l'alimentation tels que Wendy's et McDonald's sont prêts à améliorer l'expérience de leurs clients grâce à l'ASR. Dans bon nombre de leurs points de vente, ils ont déployé des modèles ASR entièrement fonctionnels pour prendre les commandes et les transmettre ensuite à la section de cuisine pour préparer la commande du client.- Télécommunication: Vodafone est l'un des plus grands fournisseurs de télécommunications au monde. Il a conçu ses services d'assistance à la clientèle et de relais téléphonique en s'appuyant sur des modèles ASR qui vous guident pour résoudre différentes requêtes et rediriger vos appels vers les services concernés.
- Voyage et transport : Google Android Auto ou Apple CarPlay sont devenus courants. La plupart des gens les utilisent pour activer les systèmes de navigation, envoyer des messages ou changer de liste de lecture musicale. Cependant, avec les progrès technologiques, ces systèmes sont de plus en plus raffinés.
L'assistant personnel intelligent BMW lancé dans sa BMW Série 3 est beaucoup plus intelligent que les assistants vocaux classiques. Il peut permettre aux conducteurs de trouver des informations relatives à la voiture et de faire fonctionner la voiture à l'aide de commandes vocales. - Médias et divertissement : L'industrie des médias utilise également l'ASR dans bon nombre de ses projets. Youtube a lancé un assistant basé sur l'IA qui génère des sous-titres automatiques en direct. Pendant que vous parlez à l'écran, l'assistant fournira les sous-titres pour rendre la vidéo accessible à un plus grand groupe d'utilisateurs de Youtube.
 Industrie alimentaire: Des géants de l'alimentation tels que Wendy's et McDonald's sont prêts à améliorer l'expérience de leurs clients grâce à l'ASR. Dans bon nombre de leurs points de vente, ils ont déployé des modèles ASR entièrement fonctionnels pour prendre les commandes et les transmettre ensuite à la section de cuisine pour préparer la commande du client.
Industrie alimentaire: Des géants de l'alimentation tels que Wendy's et McDonald's sont prêts à améliorer l'expérience de leurs clients grâce à l'ASR. Dans bon nombre de leurs points de vente, ils ont déployé des modèles ASR entièrement fonctionnels pour prendre les commandes et les transmettre ensuite à la section de cuisine pour préparer la commande du client. Télécommunication: Vodafone est l'un des plus grands fournisseurs de télécommunications au monde. Il a conçu ses services d'assistance à la clientèle et de relais téléphonique en s'appuyant sur des modèles ASR qui vous guident pour résoudre différentes requêtes et rediriger vos appels vers les services concernés.
Télécommunication: Vodafone est l'un des plus grands fournisseurs de télécommunications au monde. Il a conçu ses services d'assistance à la clientèle et de relais téléphonique en s'appuyant sur des modèles ASR qui vous guident pour résoudre différentes requêtes et rediriger vos appels vers les services concernés. Voyage et transport : Google Android Auto ou Apple CarPlay sont devenus courants. La plupart des gens les utilisent pour activer les systèmes de navigation, envoyer des messages ou changer de liste de lecture musicale. Cependant, avec les progrès technologiques, ces systèmes sont de plus en plus raffinés.
Voyage et transport : Google Android Auto ou Apple CarPlay sont devenus courants. La plupart des gens les utilisent pour activer les systèmes de navigation, envoyer des messages ou changer de liste de lecture musicale. Cependant, avec les progrès technologiques, ces systèmes sont de plus en plus raffinés. Médias et divertissement : L'industrie des médias utilise également l'ASR dans bon nombre de ses projets. Youtube a lancé un assistant basé sur l'IA qui génère des sous-titres automatiques en direct. Pendant que vous parlez à l'écran, l'assistant fournira les sous-titres pour rendre la vidéo accessible à un plus grand groupe d'utilisateurs de Youtube.
Médias et divertissement : L'industrie des médias utilise également l'ASR dans bon nombre de ses projets. Youtube a lancé un assistant basé sur l'IA qui génère des sous-titres automatiques en direct. Pendant que vous parlez à l'écran, l'assistant fournira les sous-titres pour rendre la vidéo accessible à un plus grand groupe d'utilisateurs de Youtube.
[A également lu: Qu'est-ce que la technologie Speech-To-Text et comment ça marche]
Comment Shaip peut-il aider?
Shaip est l'un des principaux services de formation en IA qui possède une expertise dans plusieurs domaines de l'IA et du ML. Ils peuvent vous aider à créer votre propre ensemble de données qui pourrait être utilisé pour différentes applications et projets.
Certains des services fournis par Shaip sont :
- Reconnaissance vocale automatisée (ASR)
- Collection de discours scénarisés
- Transcréation
- Collection de parole spontanée
- Collecte d'énoncés / Mots d'éveil,
- Synthèse vocale (TTS)
Vous pouvez profiter de ces services pour obtenir les meilleurs résultats pour vos projets basés sur l'IA. Apprenez-en plus sur ces services en contactant notre équipe d'experts dès aujourd'hui!


